
WebLLM: Bring AI Language Models to Your Browser

Over the past few years, artificial intelligence has transformed our lives significantly. Today, many people rely on AI tools to solve their problems. Tools like DeepSeek, ChatGPT, and Gemini assist users in various ways. The good news is that you can now use AI models directly in your browser without relying on the cloud. WebLLM is an in-browser LLM inference engine that makes this possible. Let us learn more about this platform. Overview of WebLLM WebLLM is an open-source, in-browser LLM inference engine developed by the MLC-AI team. It was first released in December 2024. The platform runs LLMs (Large Language Models) directly in the browser using WebGPU. You do not need to use cloud-based APIs anymore. Since WebLLM runs the model directly on your device, it eliminates the need for server-side computation, resulting in faster responses and enhanced privacy. How does WebLLM work? WebLLM is powered by the WebGPU API, a modern graphics interface designed for the web. It helps WebLLM execute complex tensor operations required for running LLMs. WebGPU API can perform deep learning computations and matrix multiplications. WebLLM loads quantized versions of language models, optimized to reduce model size and computational demands. These models are pre-trained and converted into formats compatible with in-browser execution. Quantization reduces numerical precision, which ensures low memory usage. This makes the model small enough to load and run directly in a browser. Once loaded, WebLLM runs the model entirely within the browser using WebGPU. The model processes inputs and generates outputs locally, delivering near-instant responses. WebLLM is built on MLC-LLM, a framework that compiles and optimizes AI models for efficient execution straight in web browsers. Some official supported models by WebLLM include: Llama 3 (Meta AI) Mistral (Open-weight LLM) StableLM (Stability AI) Gemma (Google’s Lightweight LLM) Key Features of WebLLM Cross-Platform Compatibility: WebLLM runs on both desktop and mobile devices. It supports almost all modern browsers, including Google Chrome and Microsoft Edge. Additionally, users can use it on several operating systems, such as Windows, macOS, and Linux. You do not need to install any additional software. No Internet Required: Once the language model is downloaded and loaded into the browser, WebLLM runs it entirely offline. People can use the model without depending on cloud services, even with limited or no internet connectivity. The offline service is just as secure and fast. WebLLM handles all computations locally, with no network delays or external dependencies. Exceptional Privacy: Since WebLLM processes data locally within the browser, there is no fear of information leakage. Your conversations and inputs remain confidential, as no remote server is involved. The platform is ideal for individuals who value privacy and are concerned about data breaches. Open Source Platform: WebLLM is an open-source architecture. Users can seamlessly integrate it into their projects. It lets users inspect the code and make modifications as per the requirements. Furthermore, open-source licensing also encourages transparency and community collaboration. Excellent Performance: Although WebLLM runs in a browser environment, it still delivers decent performance. It can generate 15 to 20 tokens per second. This AI engine also offers ultra-low latency for real-time interaction. WebLLM uses aggressive quantization, reducing 32-bit weights to 8-bit or less. This significantly lowers memory bandwidth requirements. Pros and Cons of WebLLM Like every technology, WebLLM has some strengths and limitations. Advantages WebLLM enhances privacy by running AI models directly in your browser, with no data sent to external servers. The platform runs directly in your browser—no extra software needed. It processes results in real time, so there is no noticeable latency. WebLLM is ideal for users who want to deliver AI experiences without maintaining backend servers. As an open-source platform, it gives developers access to its codebase. Users can stream AI model responses in real-time. WebLLM helps save money by eliminating the need for costly API calls and inference servers. Disadvantages The initial loading time is a bit higher, especially on slower devices. WebLLM relies on WebGPU, which may not be supported in some browsers. Future of WebLLM? The future of WebLLM is promising. Its adoption is steadily growing, thanks to key features like strong privacy and offline capabilities. As browsers and devices continue to improve, we can expect even faster and more efficient in-browser AI experiences.WebLLM can be used to build various applications, such as writing tools, chat assistants, and educational apps. Final Words WebLLM is revolutionizing AI development. It has unlocked new opportunities in building AI-powered web applications. It makes running large language models in the browser easier by supporting chat completions and streaming. If you want to run an AI language model right in your browser without sacrificing privacy, WebLLM is worth a try.
Parcel Bundler The Ultimate Guide for Beginners

The web development landscape has been continuously progressing. Today, it has become easier to optimize the performance and efficiency of a web project – thanks to bundling tools. These platforms boost productivity and save the headache of setting up and configuring different web tools. While numerous bundling tools have emerged recently, one renowned is the Parcel Bundler. This post explores the different features of Parcel Bundler. Before we get to know its features, let’s learn more about it. Parcel Bundler Overview Parcel Bundler is an advanced tool that helps web developers utilize bundle web resources. The bundler supports zero configuration. It means it does not need any configuration file to bundle web applications. Parcel Bundler is an open-source tool that supports various languages and file types. It can integrate multiple files into a single file. Parcel Bundler can bundle files like HTML, CSS, and JavaScript into a format, optimized for the web. Furthermore, it lets you optimize your codes and prepare web projects for deployment. Some well-known features of Parcel Bundler are as per below: Features of Parcel Bundler Zero Config Module Bundler Parcel Bundler supports a zero-config setup. It means developers can bundle their web applications without configuring the bundling processes. It eliminates the need for interpreting configuration files. Hot Module Replacement HMR or Hot Module Replacement is an advanced feature of Parcel Bundler. It lets developers update their web codes in real time without reloading the full page. As web developers make changes to their codes, Parcel rebuilds the changed files and updates their applications in the browser. Parcel Bundler’s HMR updates modules in the browser at runtime without refreshing the entire page. As a result, web developers retain their application while making small changes in their codes. Bundling Parcel Bundler enables users to keep all their project files together. It can bundle JavaScript, CSS, and other files together. As Parcel automatically examines the requirements of your projects, it produces optimized bundles accordingly. File Compression Parcel Bundler performs a wide range of optimizations when creating the production build. File compression is one of them. The bundler minimizes the size of files by altering their variable names. Code Minification Parcel bundler has a built-in feature for code minification. It eliminates unnecessary characters, such as spaces, comments, etc.., from web codes without influencing their functionality. Code Minification improves the performance of your web application by reducing the overall loading time. Minification starts naturally when you start your project using the production mode (Parcel Build Command) parcel build index.html The command indicates the Parcel to bundle your project specified in the index.html file. Image Optimization Parcel bundler also excels at handling image optimization. It minimizes the size of images without affecting their quality. Therefore, websites and applications load faster. There are various ways Parcel Bundler optimizes images. For example, it adjusts the compression settings of PNG and JPEG files. Moreover, it may convert the format of images. It also resizes the dimensions of images. Development Caching Parcel Bundler caches certain resources during the development to avoid reloading those files while making changes. It speeds up the building process by updating and recompiling the parts of a web application that have been changed. Development caching is an exceptionally helpful feature for large projects. Code Cleanup The parcel comes with a built-in feature to eliminate unnecessary notes. While building a website or application, we put some notes for ourselves. For instance, we write console.log in the code. Parcel removes such statements from code automatically. As a result, your codebase looks neat and clean. Tree Shaking Tree Shaking is another crucial feature of Parcel Bundler. It lets the user remove unused codes, known as dead codes, from the final bundle. The term ‘tree shaking’ gets inspiration from the idea of shaking a tree to eliminate dead leaves. Tree shaking automatically identifies the unused codes and removes them. It works perfectly with ES6 module syntax (import/export). Tree Shaking supports the static identification of imports and exports. It makes it easier to determine unused codes. To eliminate all the dead codes, tree shaking analyzes the whole dependency tree right from the entry point of an application. It traces functions, variables, or imports used and removes the rest during the bundling process. Browser Compatibility Parcel Bundler provides a smooth development experience – thanks to its browser compatibility. The tool makes sure that you get compatibility across different browsers. Below is how Parcel ensures browser compatibility Parcel integrates with Babel, and transpiles JavaScript code (ES6+ syntax) into a backward-compatible version. Consequently, it works with a diverse range of browsers. It can work with older browsers that do not support JavaScript. Installation of Parcel If you have Node.js and npm installed, you can install Parcel Bundler using the following command. // Installing Parcel Bundler globally npm install -g parcel-bundler Installing parcel globally helps you utilize the parcel command in any project folder. Conclusion Parcel Bundler is a trustworthy and efficient service for bundling web applications. Its features like zero-configuration, caching, and tree shaking give it an edge over its competitors. No matter if you are a beginner or an experienced web developer, you can leverage this technology to improve your productivity and efficiency. So what are you waiting for? Boost your web development workflow with this excellent bundling tool.
GitHub Actions: An In-depth Guide for Beginners

Actions Platform? It would not be wrong to mention that GitHub Actions has significantly transformed the workflow of web developers. This Continuous Integration and Continuous Delivery (CI/CD) platform enables them to build, test, and deploy web codes straight from GitHub. Are you a beginner? Do you want to learn how this tool can boost your productivity? Read this guide until the end. It makes you aware of the components and features of GitHub Actions. Let’s get started! What is GitHub GitHub Actions is an automated tool powered by GitHub. It supports the automation of software building, testing, and deployment within the repositories of GitHub. Since the user does not need to leave GitHub, it naturally enhances the workflow and productivity. Developers can perform repetitive tasks while reducing manual intervention. GitHub Actions utilizes a YAML file to outline different steps of a workflow. These steps include running a script, testing, deploying codes, and sending notifications. Components of GitHub Actions GitHub Actions is a powerful tool that makes web development smooth and quick. Wondering what mechanisms make GitHub Actions work so well? Let’s learn about them. Workflow A workflow is a programmed process that runs one or more jobs. This configurable process is defined by a YAML file in the .github/workflows directory in a repository. This repository can have several workflows. And each workflow can perform a different set of jobs. For instance, you can use one workflow to create and test pull requests while another to deploy your application. Events An event is a particular activity in a repository. It is like a trigger for workflows. When events occur within a repository, GitHub Actions respond to them. These events can push requests, pull requests, or other actions. Jobs Jobs are a set of steps in a workflow. They are executed under the same runner. Each step is either a shell script or an action. Scripts execute while actions run. Action An action is an application for the GitHub Actions. It performs frequently repeated tasks. The application helps web developers to reduce the number of repetitive codes they write in their workflow files. Runner A runner is a server that runs workflows when they are triggered. One runner can perform a single task at a time. Essential Features of GitHub Actions Though GitHub Actions offers various advantages to web developers, a few prominent features are below. Variable in Workflows The default GitHub actions environment variables, incorporated in every workflow, run automatically. However, users can customize the environment variables by setting them in their YAML files. In the following example, you can see how one can create custom variables for POSTGRES_HOST and POSTGRES_PORT. These variables are available in the node client.js script. jobs: demo-job: steps: – name: Connect to your PostgreSQL run: node client.js env: POSTGRES_HOST: postres POSTGRES_PORT: 5432 Addition of Scripts to Workflow GitHub Actions allow the addition of scripts to workflow. You can employ actions for running scripts and shell commands. They get executed on the selected runner. Find out how an action can use the run keyword to execute npm install –g bats on the runner in the flowing example. jobs: demo-job: steps: – run: npm install -g bats Sharing Data Between Jobs One of the crucial features of GitHub Actions is that you can reuse the jobs you created earlier. You can save files for later use as artifacts on GitHub. These files get generated while building and testing web code. These files could be screenshots, binary, test results, and package files. You can also make your file and upload it on artifacts for later use. jobs: demo-job: name: Save output steps: – shell: bash run: | expr 1+1 > output.log – name: Upload output file users: actions/upload-artifact@v3 with: name: output-log-file path: output.log Step-by-Step Creation of GitHub Action File If you want to learn the workings of the GtiHub actions workflows, here is the step-by-step guide. You will need a GitHub repository to create the GitHub actions. Set up of the GitHub Action File ⦁ Make a .github/workflows directory in your repository on GitHub in case it does not already exist. ⦁ In the directory, you may create a file name: GitHub-actions-demo.yml. ⦁ Next, copy the following YAML content into the GitHub-actions-demo.yml file. name: GitHub Actions Example on: [push] jobs: Explore-GitHub-Actions: runs-on: ubuntu-latest steps: run: echo " The job was automatically triggered by a ${{Github.event_name }} event." run: echo " This job is now running on a ${{ runner.os }} server hosted by GitHub!" run: echo " The name of your branch is ${{ GitHub.ref }} and your repository is ${{ GitHub.repository }}." name: Check out repository code user: actions/checkout@v3 run: echo " The ${{ GitHub.repository }} repository has been cloned to the runner." run: echo " The workflow is now ready to test your code on the runner." name: List files in the repository run: | Is ${{ GitHub.workspace }} run: echo " This job's status is ${{ job.status }}." ⦁ Create a new branch for this commit and begin a pull request. ⦁ To create a pull request, click Propose new file. ⦁ When you commit your workflow file to a branch within your repository, it initiates the push event and then executes your workflow. Run the Files Your next step should be running the file. ⦁ Visit github.com and go to the main page of the repository. ⦁ Beneath your repository name, click Actions. ⦁ On the left sidebar, hit the workflow you want ⦁ Under Jobs, click on the Explore-GitHub-Actions job. The above log shows the breakdown of each step carried out. You can expand these steps to view its details. Conclusion GitHub Actions is a robust automation tool that streamlines development workflows. Web developers can leverage its flexibility, automation, and integration within GitHub. In addition to this, the platform supports event-driven workflows. In this blog, we learned about components of GitHub Actions. Also, we came to know about its essential features. All-in-all, GitHub Actions is a versatile tool for developers that simplifies the
Next.js 13.5: Exploring Features and Improvements

Next.js is an open-source JavaScript framework built using React. It helps web developers make user-friendly web applications and static websites. This renowned React framework has come with its latest version, Next.js 13.5. With each new version, Next.js is getting more powerful. Released on September 19, 2023, this new edition has taken the world by storm. Let us find out what is new about it. This blog explores the exciting Next.js 13.5 features and improvements. Fast Page Loading The latest version of Next.js supports quick page loading. Next.js 13.5 has optimized its core framework. Therefore, web applications load faster without compromising on user experience. The version 13.5 features built-in optimization for fonts, scripts, images, and application scripts. Image Improvements Next.js 13.5 comes with robust image optimization capabilities. In comparison to previous versions, Next.js 13.5 is better in image resizing and compression. As a result, you can deliver your images in a perfect size and format. In addition to this, the framework has added an experimental function unstable_getImgProps(). It supports different use cases without using the <Image> component. Now you can: Work with background-image or image-set. Use <picture> media queries to carry out Art Direction or Light/Dark mode images. Work with canvas context.drawImage() or new Image(). Moreover, now the placeholder prop provides support for arbitrary data: image/ for placeholder images. Improved Startup and Refresh Time Other Next.js 13.5 improvements that are worth mentioning include fast startups and refreshes. You can notice a significant improvement in refresh and startup time. The framework is now more reliable for App router applications. If you compare this new version with the previous Next.js 13.4, it is about 22% faster in local server startup and 29% quicker in HMR (Refresh). Apart from this, it uses about 40% less memory. Next.js 13.5 has optimized expensive file system operations and removed redundant blocking synchronous calls. Caching in Next.js Apps Caching has a crucial role in web application development. It has a direct impact on user experience and performance. Besides this, it minimizes the operation cost of the application by storing rendering work and data requests. Next.js 13.5 allows users to retrieve the stored version of web applications. Since users do not fetch data from scratch every time, they experience fast web loading. Next.js 13.5 supports numerous caching mechanisms. It makes it easier for developers to carry out client-side caching. Some prominent caching mechanisms in Next.js 13.5 include: Data Cache Data Cache is one of the vital Next.js 13.5 updates. It stores the results of different data fetches across server requests and deployments. As a result, once data is fetched and stored, users can access it quickly in subsequent requests. Since the results are not coming from the source, it takes less time. Request Memoization This caching mechanism helps the server to remember the return values of functions. For instance, if the same data is being requested repeatedly in a React component tree, Next.js stores the data instead of fetching it over again. It is beneficial when the same data needs to be accessed. Full Route Cache As the name suggests, this mechanism caches the full HTML. Besides this, it also stores the React Server Component payload of a route on the server. It naturally minimizes the cost of rendering. Router Cache Next.js also stores the cache on the client’s side. It keeps the record of the React Server Component payload for every route segment. The router cache enhances the navigation experience by storing earlier visited routes and prefetching possible future routes. Improved Experience for Developer With the release of every Next.js version, the framework gets better in the developer experience. The developers can notice a noteworthy improvement in TypeScript support, documentation, and error messages. In addition to this, you get access to Next.js CLI. This tool helps you see updates for project setup and management. Metadata API Metadata API is a crucial addition to Next.js 13.5. With this Next.js 13.5 feature, you do not need to struggle with SEO metatags. Earlier, users had to create a file (head.js) to set the metatags for SEO. Next.js version 13.5 features a new way of handling static and dynamic metadata. You can export objects with static information. For dynamic data, you can export functions. This approach is more helpful for managing metadata efficiently. Stable App Router A stable app router is one of the prominent Next.js 13.5 benefits. Now you can use React server components, nested routes & layouts, and simplified data fetching confidently. These updated server components will help you build apps faster. Conclusion It is imperative to stay informed with the evolving world of web development and its latest technologies. Today, Next.js is a keystone of react-based web development. With Next.js 13.5, you enjoy a range of new features and improvements. Whether it is a developer experience, performance, or security, Next.js 13.5 can keep you ahead in the competitive web development world.
Ceph Persistent Storage for Kubernetes with Cephfs

Kubernetes is a prominent open-source orchestration platform. Individuals use it to deploy, manage, and scale applications. It is often challenging to manage stateful applications on this platform, especially those having heavy databases. Ceph is a robust distributed storage system that comes to the rescue. This open-source storage platform is known for its reliability, performance, and scalability. This blog post guides you on how to use Ceph persistent storage for Kubernetes with Cephfs. So let us learn the process step-by-step. Before we jump into the steps, you must have an external Ceph cluster. We assume you have a Ceph storage cluster deployed with Ceph Deploy or manually. Step 1: Deployment of Cephfs Provisioner on Kubernetes Deployment of Cephfs Provisioner on Kubernetes is a straightforward process. Simply log into your Kubernetes cluster and make a manifest file to deploy the RBD provisioner. It is an external dynamic provisioner that is compatible with Kubernetes 1.5+. vim cephfs-provisioner.yml Include the following content within the file. Remember, our deployment relies on RBAC (Role-Based Access Control). Therefore, we will establish the cluster role and bindings before making the service account and deploying the Cephs provisioner. — kind: Namespace apiVersion: v1 metadata: name: cephfs — kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cephfs-provisioner namespace: cephfs rules: – apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] – apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] – apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] – apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] – apiGroups: [""] resources: ["services"] resourceNames: ["kube-dns","coredns"] verbs: ["list", "get"] — kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cephfs-provisioner namespace: cephfs subjects: – kind: ServiceAccount name: cephfs-provisioner namespace: cephfs roleRef: kind: ClusterRole name: cephfs-provisioner apiGroup: rbac.authorization.k8s.io — apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: cephfs-provisioner namespace: cephfs rules: – apiGroups: [""] resources: ["secrets"] verbs: ["create", "get", "delete"] – apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] — apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: cephfs-provisioner namespace: cephfs roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: cephfs-provisioner subjects: – kind: ServiceAccount name: cephfs-provisioner — apiVersion: v1 kind: ServiceAccount metadata: name: cephfs-provisioner namespace: cephfs — apiVersion: apps/v1 kind: Deployment metadata: name: cephfs-provisioner namespace: cephfs spec: replicas: 1 selector: matchLabels: app: cephfs-provisioner strategy: type: Recreate template: metadata: labels: app: cephfs-provisioner spec: containers: – name: cephfs-provisioner image: "quay.io/external_storage/cephfs-provisioner:latest" env: – name: PROVISIONER_NAME value: ceph.com/cephfs – name: PROVISIONER_SECRET_NAMESPACE value: cephfs command: – "/usr/local/bin/cephfs-provisioner" args: – "-id=cephfs-provisioner-1" serviceAccount: cephfs-provisioner Next, apply the manifest. $ kubectl apply -f cephfs-provisioner.yml namespace/cephfs created clusterrole.rbac.authorization.k8s.io/cephfs-provisioner created clusterrolebinding.rbac.authorization.k8s.io/cephfs-provisioner created role.rbac.authorization.k8s.io/cephfs-provisioner created rolebinding.rbac.authorization.k8s.io/cephfs-provisioner created serviceaccount/cephfs-provisioner created deployment.apps/cephfs-provisioner created Make sure that the Cephfs volume provisioner pod is in the operational state. $ kubectl get pods -l app=cephfs-provisioner -n cephfs NAME READY STATUS RESTARTS AGE cephfs-provisioner-7b77478cb8-7nnxs 1/1 Running 0 84s Step 2: Obtain the Ceph Admin Key and Create a Secret on Kubernetes Access your Ceph cluster and retrieve the admin key to be used by the RBD provisioner. sudo ceph auth get-key client.admin Save the value of the admin user key displayed by the above command. Later, we will incorporate this key as a secret in Kubernetes. kubectl create secret generic ceph-admin-secret \ –from-literal=key='<key-value>' \ –namespace=cephfs Where <key-value> is your Ceph admin key. Verify the creation by using the following command. $ kubectl get secrets ceph-admin-secret -n cephfs NAME TYPE DATA AGE ceph-admin-secret Opaque 1 6s Step 3: Make Ceph Pools for Kubernetes and Client Key To run a Ceph file system, you will need at least two RADOS pools, one for data and another for metadata. Usually, the metadata pool contains only a few gigabytes of data. Generally, individuals use 64 or 128 for large clusters. Therefore, we recommend a small PG count. Now let us make Ceph OSD pools for Kubernetes: sudo ceph osd pool create cephfs_data 128 128 sudo ceph osd pool create cephfs_metadata 64 64 Create a Ceph file system on the pools. sudo ceph fs new cephfs cephfs_metadata cephfs_data Confirm Ceph File System Creation. $ sudo ceph fs ls name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] UI Dashboard Confirmation Step 4: Make Cephfs Storage Class on Kubernetes A StorageClass serves as a means to define the “classes” of storage you offer in Kubernetes. Let’s create a storage class known as “Cephrfs.” vim cephfs-sc.yml Add the following content to the file: — kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: cephfs namespace: cephfs provisioner: ceph.com/cephfs parameters: monitors: 10.10.10.11:6789,10.10.10.12:6789,10.10.10.13:6789 adminId: admin adminSecretName: ceph-admin-secret adminSecretNamespace: cephfs claimRoot: /pvc-volumes Where: ⦁ Cephfs is the name of the StorageClass to be created. ⦁ 10.10.10.11, 10.10.10.12 & 10.10.10.13 are the IP addresses of Ceph Monitors. You can list them with the command: $ sudo ceph -s cluster: id: 7795990b-7c8c-43f4-b648-d284ef2a0aba health: HEALTH_OK services: mon: 3 daemons, quorum cephmon01,cephmon02,cephmon03 (age 32h) mgr: cephmon01(active, since 30h), standbys: cephmon02 mds: cephfs:1 {0=cephmon01=up:active} 1 up:standby osd: 9 osds: 9 up (since 32h), 9 in (since 32h) rgw: 3 daemons active (cephmon01, cephmon02, cephmon03) data: pools: 8 pools, 618 pgs objects: 250 objects, 76 KiB usage: 9.6 GiB used, 2.6 TiB / 2.6 TiB avail pgs: 618 active+clean Once you have updated the file with the accurate value of Ceph monitors, give the Kubectl command to make the StorageClass. $ kubectl apply -f cephfs-sc.yml storageclass.storage.k8s.io/cephfs created Next, list all the available storage classes: $ kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE ceph-rbd ceph.com/rbd Delete Immediate false 25h cephfs ceph.com/cephfs Delete Immediate false 2m23s Step 5: Do Testing and Create Pod Create a test persistent volume claim to ensure that everything is smooth. $ vim cephfs-claim.yml — kind: PersistentVolumeClaim apiVersion: v1 metadata: name: cephfs-claim1 spec: accessModes: – ReadWriteOnce storageClassName: cephfs resources: requests: storage: 1Gi Apply manifest file $ kubectl apply -f cephfs-claim.yml persistentvolumeclaim/cephfs-claim1 created The successful binding will show the bound status. $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ceph-rbd-claim1 Bound pvc-c6f4399d-43cf-4fc1-ba14-cc22f5c85304 1Gi RWO ceph-rbd 25h cephfs-claim1 Bound pvc-1bfa81b6-2c0b-47fa-9656-92dc52f69c52 1Gi RWO cephfs 87s Next, we can launch a test pod using the claim we made. First, create a file to store that data: vim cephfs-test-pod.yaml Add content
How to choose a Freelance Full Stack Web Developer

Hiring a full-stack web developer is a crucial decision for any web development company. The kind of candidate they choose can make or break their project’s aspiration. Full-stack web development requires comprehensive knowledge of developing, testing and deploying web applications. Consequently, you can’t hire any random developer you find on a job portal or the web. Companies that want to recruit a freelance full-stack web developer but don’t know how to get started must read this post. Below, we have accumulated factors to consider when selecting a full-stack web developer. So let’s get started. Step 1: Define Your Project Requirements Clearly Before you begin searching for a full-stack web developer, learn your project requirements. Define the scope of work, the end goal, and the technologies required for the same. It will help you determine the search criteria for a suitable web developer. Step 2: Consider the Skills of the Developer A full-stack web developer is a versatile professional. They must be skilled in both front-end and back-end development. Ensure the developer has the required skill set your project needs. Make a list of programming languages, software, and frameworks needed for the project. On this basis, you can decide the kind of web developer you need. Generally, skills to look for in a full-stack web developer include: Front-end development: Expertise in HTML, CSS, and JavaScript. Furthermore, the developer must have experience in front-end libraries and frameworks. Back-end Development: Knowledge of programming languages, including Node.js and Python is crucial. It will be advantageous if the developer is familiar with back-end frameworks such as Flask or Express. Database Management: Knowledge of different kinds of databases, both SQL and NoSQL, is also essential. Step 3: Check Portfolio Don’t forget to check the portfolio and experience of your potential web developer. A strong portfolio validates the skills and capability of a developer to work on real-world projects. You can visit their websites to learn about past clients and projects they completed. Though certifications alone do not confirm expertise, you can check relevant certifications to validate the developer’s skills. Step 4: Geographical Location of Freelancer The accessibility of the internet has removed all the limits of geographical boundaries. In this digital era, you do not need to confine yourself to locally available talents. You can hire developers from all over the globe. Make sure the freelancer can work in the time zone you prefer. Step 5: Set a Clear Budget and Timeline Before you finalize a full-stack developer and sign a contract, set a clear budget and timeline for the project. It will help you manage the overall cost and period of your project. The cost of hiring a full-stack developer depends on the experience and timeline of the project. Some freelancers charge on an hourly basis, while others have a set fee. Discuss the budget with your freelancer by describing your project requirements. Also, ask them about the expected timeline for the project. You can break down the timeline for your project into different stages. It will help you manage your time effectively. Step 6: Communication Skills You cannot deny the importance of effective communication in web development. Go for a full-stack developer having strong communication skills. A developer has to work with a website designer, other developers, and project managers. An effective communication ensures a smooth workflow. Developers with good communication skills can efficiently convey ideas, address concerns, and update managers about the work progress. Step 7: Team Collaboration The developer you choose must have the ability to work well with others. In a modern web development environment, developers, designers, and testers work together symphonically. Step 8: Conduct Interviews Once you have shortlisted some possible full-stack developers, conduct interviews to choose the most suitable one. An interview will help you get more insight into whether or not a candidate is proficient in meeting project requirements. Evaluate the technical expertise, background, and communication skills of candidates carefully. To assess technical knowledge, you can give programming exercises. If you do not have adequate technical experience and do not know how to check the skills of a full-stack web developer, give preference to a senior full-stack web developer with a lot of experience. Step 9: Make Clear Contracts Make sure billing contracts are clear to you and your freelancers. The contract clearly defines the responsibility of a freelancer and payment terms. The payment terms must include the details of the wage structure, rate, payment schedule and more. These are a few things to consider when hiring a full-stack web developer. Let us learn whether a freelancer or company is a good choice for you. Full-Stack Web Developer: Freelancer vs. Company (Quick Comparison) Whether to choose a freelancer or a company depends on your project requirements, budget and preferences. When you work with a freelancer, you get the following benefits: Affordability Most freelancers charge a lower fee than an established web development company. If you have a limited budget, choosing a freelancer is a good decision. Flexible You have the flexibility to hire freelancers for short-term, long term or just for a specific task. Personalized Attention Since you will work directly with the developer, it will form a close working relationship. Therefore, the freelancer gives personalized attention to your project. The advantages of working with a web development company are below: More Resources Companies have more tools and technologies to manage your projects comparatively. An agency can employ dedicated managers on your project. Scalability As your project grows, you will need more resources to expand your services. Companies can better handle scalability. Delivery Time With most companies, you can expect quick delivery of your project. Conclusion If you are a small company, hiring a freelance web developer is beneficial for you. They are not just affordable but also flexible. On the other hand, if you are a big company with unlimited tasks and a substantial budget, choose a web development company.
Types of NoSQL Databases: Everything You Need to Know About Them
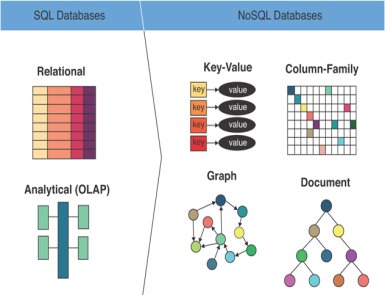
NoSQL or Not Only SQL is a renowned database management system (DBMS) that manages a large volume of unstructured or semi-structured data. Since it eliminates various limitations of conventional relational databases, the NoSQL database has become popular. Google, Facebook, Amazon, and Netflix are some reputable companies that use NoSQL. This blog makes you aware of different types of NoSQL databases. In addition, you will learn their features. Before we move further, let’s find out how NoSQL is diverse from SQL. SQL vs. NoSQL Databases: Quick Comparison Type SQL databases are Relational Databases, while NoSQL databases are known as non-relational databases. Language of Query SQL databases use a Structured Query Language to do jobs like Delete, Select, Update, and Insert. On the other hand, NoSQL has its query language for manipulating data. NoSQL works on a framework or API, depending on the type of database. Expandability Traditional SQL databases are vertically scalable. You can enhance their performance by upgrading hardware. On the contrary, NoSQL databases are horizontally scalable from the ground up. Consequently, they are better at handling large amounts of data and traffic. Property Followed SQL follows ACID (Atomicity, Consistency, Isolation, and Durability) transactions when it comes to managing data integrity. NoSQL databases use the CAP theorem (Consistency, Availability, and Partition Tolerance). Types of NoSQL Databases We can categorize NoSQL databases into the following 4 types. Each has its pros and limitations. You can choose them based on your requirements. Let us learn about them in detail. Key Value Pair Database Key-Value Pair Database is one of the simplest types of NoSQL Databases. It is a non-relational database storing data elements in key-value pairs. Key-Value Pair Database can handle heavy loads of data. It stores data as a hash map and has two columns, i.e., the Key and the Value. Each database key is different, while the value can be String, Binary Large Objects, or JavaScript Object Notation. The three major features of the Key Value Pair Database are speed, straightforwardness, and scalability. Generally, this type of database is used for creating dictionaries, user profiles, user preferences, etc. Graph-Based Database The graph-based database helps users store entities and relations between those entities. Commonly, this database is used to store data on social networking websites, fraud detection systems, healthcare networks, and more. The graph-based database stores the data as a node. The connections between nodes are known as edges. Every edge and node has a different identifier. The database allows users to find the relationship between the data with the help of links. Unlike relational databases, graph-based databases are multi-relational. A few well-known graph-based databases are Flock DB, Neo4J, Infinite Graph, etc. All-in-all, we can say that a graph-based database stores, manages, and queries data as a graph structure. Column Oriented Database Column Oriented Database is a non-relational database. The database lets you store data in rows and read it row by row. It is like a collection of columns like we see in a table. Each column stores one type of information. The database reads and retrieves the data at high speed. You can run analytics on a limited number of columns to read those columns without consuming memory on unwanted data. Column Oriented Database performs queries like Count, SUM, AVG, and MIN quite quickly. Therefore, the database is used for analytics and reporting, data warehousing, and library card catalogs. Document-Oriented Database A document-oriented database is one of the prominent types of NoSQL databases. It stores and manages data like we organize documents in the real world. Although the data is stored and retrieved as a key-value pair, the value is stored as a document. The database uses the JSON, XML, or BSON documents to store the data. Users can store and retrieve documents from their networks in a form that is closer to the data objects. Therefore, negligible translation is needed to access and use data in an application. Document-Oriented Database supports flexible schema, scalability, and quick retrieval. MongoDB and Couchbase are two fine examples of these databases. This database is used in CMS (Content Management Systems), E-commerce websites, gaming applications, collaboration tools, etc. So these are four types of NoSQL databases. Let’s find out why this database system is getting popular. Features of NoSQL NoSQL has several advancements over traditional databases. We have listed a few significant ones. Compatible with Multiple Data Models Like relational databases, NoSQL is not strict. It can handle multiple data models. Additionally, the database can manage structured, semi-structured, and unstructured data with the same speed. Schema Flexibility Unlike conventional database systems, Not SQL databases do not require a fixed schema. It supports relaxed schemas. NoSQL is capable of managing different data formats and structures. As it does not have a strict predefined schema, it permits changes in data models. Scalable As mentioned above, the NoSQL database is scalable. Users can scale it horizontally by adding more modes and servers. Consequently, it is suitable for websites and web applications with continuously growing data. Excellent Uptime NoSQL databases have excellent uptime. They support serverless architecture and create multiple copies of data on various nodes. Consequently, businesses manage their database smoothly with minimal downtime. If one note breaks down, another takes its place and gives access to the data copy. Examples of NoSQL Now you know the different types of NoSQL databases and their uses. Below are some examples of them. Document Database MongoDB is a well-known document-oriented database. It stores data in JSON-like documents. MongoDB is popular for its scalability and flexibility. Column Database Apache Cassandra is a well-known column-based database system that handles large amounts of data across different commodity servers. Graph Database Amazon Neptune is a managed graph database service by AWS. It can work with both RDF graph and property graph models. Key-Value Database Amazon DynamoDB is a database service that provides high uptime and low-latency key-value storage. This service from Amazon Web Service is the epitome of a Key-Value type database. Conclusion Various types of NoSQL databases are a crucial
The Ultimate Guide to GitLab CI/CD: Along with Example of Building CI/CD Pipeline for Python

No one can deny the significance of CI (Continuous Integration) and CD (Continuous Deployment) in software development. They enable a coder to integrate and deploy software codes and identify possible issues simultaneously. Consequently, the process naturally saves the time and effort of a developer. While several platforms support CI/CD, GitLab has grown in popularity. It automates software development in several aspects. This guide makes you aware of the features of GitLab CI/CD. In addition, you will learn to build CI/CD pipelines on GitLab. So let us get started. What is GitLab CI/CD? CI stands for Continuous Integration, while CD for Continuous Deployment/Delivery. CI supports the continuous integration of code changes from various contributors into a shared repository. On the other hand, CD allows code deployment while being developed. GitLab CI/CD is a set of tools and techniques automating software development. It enables users to create, test and deploy code changes inside the GitLab to the end users. The platform aims to support consistent workflow and improve the speed and quality of code. Features of GitLab CI/CD GitLab has several benefits over conventional software development methods. Some key benefits are as per below: ⦁ GitLab keeps CI/CD and code management in the same place. ⦁ It’s a cloud-hosted platform. You do not need to worry about setting up and managing databases or servers. ⦁ You can sign up for the subscription plan that suits your budget. ⦁ You can run different types of tests, such as unit tests, integration tests, or end-to-end tests. ⦁ GitLab automatically builds and tests your code changes as they are pushed to the repository. ⦁ Since GitLab CI/CD is built-in, there is no need for plugin installation. ⦁ The platform supports continuous code collaboration and version control. The Architecture of GitLab CI/CD GitLab CI/CD architecture consists of the following components: GitLab Server Like every online platform, GitLab works on a server. The GitLab server is accountable for hosting all your Git repositories. It helps you keep your data on the server for your client and team. The GitLab server hosts your applications and configures the pipeline. It also manages the pipeline execution and assigns jobs to the runners available. GitLab.com is run by a GitLab instance that further comprises an application server, database, file storage, background workers, etc. Runners Runners are applications that run CI/CD pipelines. GitLab has several runners configured. Every user can access these runners on gitlab.com. Users are allowed to set up their own GitLab runners. Jobs Jobs are tasks performed by the GitLab pipeline. Each job has a unique name and script. Each script gets finished one after the other. A user moves on to the next one only when the previous one is complete. Stages Stages are referred to the differences between jobs. They ensure the completion of jobs in the pipeline. For instance, testing, building, and deploying. Pipeline The pipeline is a complete set of stages. Every stage comprises single or multiple jobs. You can find various types of pipelines in GitLab. These types include basic pipelines, multi-branch pipelines, merge request pipelines, parent-child pipelines, scheduled pipelines, multi-job pipelines, etc. Commit Commit is a record of changes made in the code or files. It is similar to what we see in a GitHub repository. So this is an architecture of GitLab CI/CD. Let us learn how to build a simple CI/CD pipeline with GitLab. Building a Simple CI/CD pipeline for a Python Application 1. First, create an account on GitLab. 2. Next, create a new project. You get four different options to create your project. Choose any method convenient to you. In this example, we will import the project from GitHub. 3. Once the project is set up, create a yaml file. Give it a name that is easy to remember. For example, .gitlab-ci.yml. Above is an example of tests run. Image: It is the image we intend to use to execute our script. before_script: Before script helps you install the prerequisites required to run your scripts. It also includes commands you need to run before the script command. after_script: This script outlines commands running after each job. It may also include failed jobs handling. To add the Python image, we are using images available on DockerHub. 4. Under the CI/CD tab, you will find the ‘Jobs’ tab to get detailed logs and troubleshooting. 5. Next, create an account on DockerHub. You can find the image for Docker on Dockerhub. 6. Go back to the yaml script and write a script to upload the docker image to the repository. You will need to use credentials. To ensure the safety of credentials, use another GitLab feature. Go to Settings-> CI/CD-> Variables Here you can make global variables that you can refer to in the code. If you use the masked variable option, it will prevent the visibility of variable content in logs. 7 Next, upload the image to a private repository. Tag the repository name in Dockerhub. It will help you when writing the Docker push command. The stage clause guarantees that each stage will execute one after another. You can create variables both globally and inside the jobs. You can use them as: $var1 8. In our example, we are following docker in the docker concept. It means we have to make docker available inside its container. The docker client and daemon are inside the container to execute the docker command. 9. Now it is time for the preparation of the deployment server. The process involves configuring the tools and settings to automate the deployment. You can use any remote server. In this example, we are using an Ubuntu server. 10. We used the following command to create a private key. ssh-keygen The method to create a private variable is the same as mentioned in step 6. 11. Next, add the yaml script. Before using the docker run command, stop existing containers. Especially those running on the same port. For this, we have added line 37. By default,
Keras Core 3.0 — Pioneering the Next Frontier in Deep Learning APIs

In the dynamic landscape of artificial intelligence, where breakthroughs occur in rapid succession and the boundaries of what’s possible are constantly pushed, the Keras framework has emerged as a steadfast companion for machine learning practitioners and researchers. With the advent of Keras Core 3.0, the framework embarks on a transformative journey, poised to redefine the very essence of capabilities, performance, and adaptability, and solidify its position as a trailblazer in the realm of deep learning. This article delves into the evolution of Keras, highlights the remarkable features of version 3.0, and explores its compatibility with various backends. Understanding Keras — A Journey from Inception to Innovation Keras, born from the visionary mind of François Chollet in 2015, swiftly rose to prominence as a high-level neural networks API known for its intuitive design and unparalleled experimentation agility. Its initial incarnation and subsequent integration with TensorFlow marked a pivotal moment, propelling Keras into the limelight of machine learning tools. As the AI landscape evolved, Keras adapted in tandem, shaping itself to meet the diverse demands of an ever-expanding user community. Now, with the unveiling of Keras Core 3.0, this evolutionary saga culminates in a symphony of enhancements that not only elevate the framework’s capabilities but also redefine its role as an indispensable asset in the arsenal of AI practitioners. Redefining Possibilities — Unveiling Keras 3.0’s Game-Changing Features Embracing the Multi-Backend Landscape Keras 3.0 emerges as a trailblazer with its unprecedented support for multiple backends. While its roots are anchored in TensorFlow, this version casts a wider net, inviting frameworks like jAX and PyTorch into its fold. The result? A harmonious coexistence that empowers researchers and practitioners to wield their preferred framework without renouncing the prowess of Keras. Precision Perfected — Advanced Performance Optimization Keras Core 3.0 doubles down on performance optimization, seamlessly weaving techniques like mixed-precision training and distributed training into its fabric. The result is a turbocharged training process and maximized hardware resource utilization. These optimization strategies work behind the scenes, enabling users to focus on the art of model development and experimentation, confident that the framework is orchestrating the complex ballet beneath. Expanding the Horizons — A Flourishing Ecosystem The Keras ecosystem flourishes with renewed vigour in Keras 3.0. The framework’s enhanced support for KerasCV and KerasNLP, specialized libraries tailored for computer vision and natural language processing, empowers it to excel in these domains. This synergy doesn’t just streamline the development process; it equips users with an extensive toolkit to conquer the intricate challenges inherent in these fields. Uniting the Diverse — Cross-Framework Compatibility Keras Core 3.0 ushers in an era of harmony across deep learning frameworks. Models crafted in Keras effortlessly traverse the boundaries between TensorFlow, jAX, and PyTorch backends, reflecting a unification in an ecosystem historically divided. This seamless compatibility erases barriers, fostering an environment of collaboration and experimentation, where diverse tools coalesce to drive innovation. Evolution by Design — The Philosophy of Progressive Disclosure Keras 3.0 embodies the ethos of progressive disclosure, catering to both novices and seasoned practitioners. The API unfolds in a manner that facilitates the gentle onboarding of newcomers while gradually unveiling the advanced features craved by experts. This balanced approach ensures Keras remains accessible and indispensable, irrespective of users’ proficiency levels. A Stateless Symphony of Design — The Stateless API Paradigm The introduction of the stateless API marks a paradigm shift in Keras 3.0. Aligned with the trend of integrating functional programming concepts in deep learning, this design choice fosters modular architecture, encourages code reusability, and champions clean code organization. This leap not only elevates the development experience but also fortifies code maintenance and collaborative prowess. Navigating the Possibilities — Keras for TensorFlow, jAX, and PyTorch Embarking on the Voyage: Installation Embarking on the journey with Keras Core 3.0 is an effortless endeavour. Installation guides for each supported backend are readily available in the official documentation, providing users the freedom to opt for the backend that resonates with their ethos and project requisites. This adaptability cements Keras as an indispensable entity amid the ever-shifting currents of AI technology. For installation, $ pip install keras-core import keras_core as keras Aligning with the Core: Backend Configuration Configuring the backend is a seamless ritual, often requiring a mere few lines of code. This configuration determines the engine propelling Keras—be it TensorFlow, jAX, or PyTorch. This flexibility empowers users to fluidly transition between backends, paving the way for efficient exploration and experimentation. Run the following command for backend configuration: $ export KERAS_BACKEND="jax" $ python train.py Or $ KERAS_BACKEND=jax python train.py Mastery in Action: Integrating KerasCV and KerasNLP The integration of KerasCV and KerasNLP into Keras Core 3.0 paints a transformative landscape. KerasCV brings forth a symphony for computer vision tasks, providing dedicated APIs and pre-fabricated models for image classification, object detection, and segmentation. Meanwhile, KerasNLP empowers users to navigate the challenges of natural language processing with access to cutting-edge language models, tokenization tools, and sequence manipulation layers. And here is some KerasCV usage example: import keras_cv import keras_core as keras filepath = keras.utils.get_file(origin="https://i.imgur.com/gCNcJJI.jpg") image = np.array(keras.utils.load_img(filepath)) image_resized = ops.image.resize(image, (640, 640))[None, …] model = keras_cv.models.YOLOV8Detector.from_preset( "yolo_v8_m_pascalvoc", bounding_box_format="xywh", ) predictions = model.predict(image_resized) A Confluence of Innovation: In the ever-accelerating tapestry of deep learning, Keras Core 3.0 emerges as a beacon of innovation and adaptability. With its embrace of multiple backends, advanced performance optimization, amplified ecosystem, cross-framework harmony, philosophy of progressive disclosure, and the advent of the stateless API, Keras 3.0 redefines itself as the quintessential deep learning API. It resonates across the spectrum of users—novices venturing forth and experts charting the boundaries of possibility. As the grand symphony of deep learning unfolds, Keras Core 3.0 remains a steadfast companion, empowering developers to manifest their visions with unmatched finesse and precision.
NetDevOps — A Comprehensive Guide with Components and Obstacles
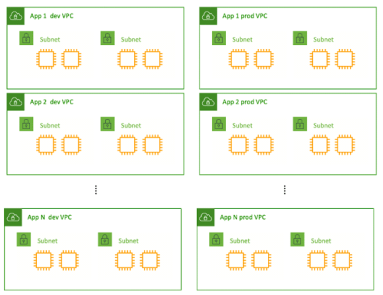
Considering the automation through Agile development processes, the software development industry has experienced a massive shift towards NetDevOps. The credit goes to its underlying network infrastructure offering network automation to fast-paced modern businesses. Since the non-DevOps approach hovers around tools, developers may experience a lack of traceability, testing, and collaboration. Here NetDevOps can help you cop with these limitations and eliminate security vulnerabilities while ensuring expected performance. Similarly, there’s a glut of things you need to know about NetDevOps if you’re looking to incorporate it into your development process. This guide will lead you to the various NetDevOps components and obstacles for a better understanding. What is NetDevOps and Why is it Worth Using? As the term describes itself, NetDevOps is a technical blend of Networking and DevOps. It streamlines the DevOps principles for the deployment and management of network services. If we dig deeper, NetDevOps apply CI/CD DevOps concepts to networking activities for faster delivery. In addition to this, its automated workflows bolster the abstraction, codification, and Infrastructure as Code (IaC) implementation. NetDevOps also eliminate the configuration drift to embed quality and resiliency within the network. In a nutshell, it improves agility by driving clear workflows aiding auditing, governance, and troubleshooting. Challenges You May Face During NetDevOps Development Risk Aversion One of the challenges that organizations may face during NetDevOps development is risk aversion. Many companies are hesitant to adopt new technologies and practices due to the fear of potential failures or disruptions to their existing network infrastructure. This risk aversion can hinder the adoption of NetDevOps methodologies, which emphasize automation, continuous integration, and continuous delivery. To address this challenge, organizations need to focus on building trust by demonstrating the benefits and success stories of NetDevOps implementation. Technical Debt Technical debt refers to the accumulated shortcuts, workarounds, and suboptimal code or configurations that result from rushed or incomplete implementation of network automation processes. This can lead to various issues, including increased complexity, reduced maintainability, and decreased scalability. To mitigate technical debt, organizations should prioritize code quality, conduct regular code reviews, and follow established best practices and coding standards. Implementing automated testing frameworks and leveraging continuous integration and delivery pipelines can help identify and address technical debt early in the development process. Skills Shortage NetDevOps development requires a unique set of skills that combine network engineering, software development, and automation expertise. However, finding individuals with a strong skill set in these areas can be challenging due to the shortage of qualified professionals. To address this issue, organizations can invest in training and upskilling their existing network and IT teams. This can include providing access to relevant courses, certifications, and hands-on training programs. Collaboration with external training providers or universities can also help bridge the skills gap. Documentation Effective documentation plays a crucial role in NetDevOps development, as it ensures that network configurations, automation workflows, and troubleshooting processes are well-documented and accessible to the team. However, maintaining up-to-date and comprehensive documentation can be challenging, especially when changes occur rapidly in dynamic network environments. Organizations can address this challenge by adopting documentation frameworks and tools that facilitate automated documentation generation. Version control systems, wiki platforms, and collaborative document editing tools can also help streamline the documentation process. Unstandardized Data NetDevOps development relies on gathering and analyzing network data to drive automation and decision-making processes. However, network data can be highly diverse and unstandardized, making it challenging to extract meaningful insights and build reliable automation workflows. Organizations should invest in data normalization and standardization techniques to ensure consistency and compatibility across different data sources. This can include using standardized data models, implementing data transformation pipelines, and leveraging data analytics tools for data cleansing and preprocessing. Tool Limitations NetDevOps development often requires the use of various tools and technologies, including network configuration management systems, automation frameworks, and orchestration platforms. However, tool limitations can arise, such as a lack of integration capabilities, limited scalability, or inadequate support for specific network devices or protocols. To overcome these challenges, organizations should thoroughly evaluate and choose tools that align with their specific requirements and network environment. They should also consider open-source solutions that offer flexibility and community support. Top NetDevOps Components Modularity Modularity is a key component of NetDevOps, enabling the creation of flexible and scalable network architectures. By breaking down network systems into modular components, organizations can easily adapt and scale their networks as per evolving requirements. Modularity facilitates the deployment of microservices, allowing for the independent development and deployment of specific network functionalities. This approach not only enhances agility but also simplifies troubleshooting and maintenance, as issues can be isolated to specific modules. For instance, using containerization technologies like Docker, network functions can be encapsulated within lightweight, portable containers, ensuring consistent behavior across different environments. Example 1 – Multiple applications in a single VPC network architecture Example 2 – Single application per VPC network architecture Cultural Changes Cultural changes play a crucial role in successfully implementing NetDevOps. Traditionally, network and operations teams operated in silos, with limited collaboration between them. However, NetDevOps encourages a cultural shift towards increased collaboration, communication, and shared responsibility. By fostering a DevOps culture, organizations can break down barriers between different teams, promoting a collaborative approach to network management. This cultural shift involves embracing shared goals, establishing cross-functional teams, and encouraging continuous learning and skill development. Automation and Infrastructure as Code Automation and Infrastructure as Code (IaC) are pivotal components of NetDevOps, enabling organizations to achieve faster and more efficient network deployments. Automation eliminates manual, error-prone tasks and accelerates the provisioning and configuration of network devices. Tools like Ansible, Puppet, or Chef enable the automation of network device configurations, ensuring consistency and reducing human errors. Infrastructure as Code allows network infrastructure to be defined and managed through machine-readable configuration files, promoting version control and reproducibility. Continuous Integration/Continuous Deployment Continuous Integration/Continuous Deployment (CI/CD) practices are integral to NetDevOps, enabling organizations to rapidly and reliably deploy network changes. CI/CD pipelines automate the process of integrating code changes, testing them, and deploying them to