
Django 5.0: What is New in It?

Django is an open-source Python web framework. It makes the web development process fast and straightforward through its collection of modules. Since its initial release in 2005, the framework has come a long way. With every new update, it is getting more and more robust. Let’s discover what new features and updates it brings in Django 5.0. Significant Updates in Django 5.0 Released on 4 December 2023, Django 5.0 introduces numerous updates to enhance the web development experience. Some of the primary improvements in Django are as per below: Straightforward Rendering of Form Fields One of the notable improvements you can notice in Django 5.0 is that Form Fields are easy to render now. Form fields in Django have numerous elements, such as descriptive labels, help text, error labels, etc. It was always tiresome to lay out all manually. Thankfully in this new version, you don’t need to bother about it. Django 5 features field group templates. These templates simplify the rendering of all form field components, such as widgets, help text, labels, errors, and more. Earlier: <form> … <div> {{ form.name.label_tag }} {% if form.name.help_text %} <div class="helptext" id="{{ form.name.auto_id }}_helptext"> {{ form.name.help_text|safe }} </div> {% endif %} {{ form.name.errors }} {{ form.name }} <div class="row"> <div class="col"> {{ form.email.label_tag }} {% if form.email.help_text %} <div class="helptext" id="{{ form.email.auto_id }}_helptext"> {{ form.email.help_text|safe }} </div> {% endif %} {{ form.email.errors }} {{ form.email }} </div> <div class="col"> {{ form.password.label_tag }} {% if form.password.help_text %} <div class="helptext" id="{{ form.password.auto_id }}_helptext"> {{ form.password.help_text|safe }} </div> {% endif %} {{ form.password.errors }} {{ form.password }} </div> </div> </div> … </form> Now: <form> … <div> {{ form.name.as_field_group }} <div class="row"> <div class="col">{{ form.email.as_field_group }}</div> <div class="col">{{ form.password.as_field_group }}</div> </div> </div> … </form> Database Generated Model Field The database-generated model field is another prominent update you can notice in Django 5.0. The latest GeneratedField in Django lets users create database-generated columns. The good thing is that all database backends support it. It is going to be beneficial for fields computed from other fields. For example: from django.db import models from django.db.models import F class Square(models.Model): side = models.IntegerField() area = models.GeneratedField( expression=F("side") * F("side"), output_field=models.BigIntegerField(), db_persist=True, ) This function can significantly improve the efficiency of the database. Moreover, it maintains the integrity of data. Python Compatibility Django is keeping pace with the ever-evolving Python language. With Django 5.0, users can relish the latest Python features and improvements. This new version supports Python 3.10, 3.11, and 3.12. Not only does it ensure the best performance but also improves security. Now developers can relish the full potential of Django 5.0. Facet Filters in the Admin The Django 5.0 comes with facet counts for applied filters on the admin change list. Developers can toggle this feature using UI (User Interface). It improves the admin interface by presenting facet counts alongside filters. Users can now get a quick insight into the distribution of data. Write Field Choice Easily In the earlier version of Django, it was challenging to list field choices. Users had to make an inconvenient arrangement of 2-tuples or Enumeration subclasses to list the choices available to Field.choices and ChoiceField.choices objects. See the following example: HQ_LOCATIONS = [ ("United States", [("nyc", "New York"), ("la", "Los Angeles")]), ("Japan", [("tokyo", "Tokyo"), ("osaka", "Osaka")]), ("virtual", "Anywhere"), ] Nevertheless, this latest version lets you use concise declarations with the help of dictionary mappings: HQ_LOCATIONS = { "United States": {"nyc": "New York", "la": "Los Angeles"}, "Japan": {"tokyo": "Tokyo", "osaka": "Osaka"}, "virtual": "Anywhere", } It simplifies choices to encode as literals. AsyncClient Django 5.0 features additional asynchronous methods to the Client as well as AsyncClient. It supports asynchronous testing of Django applications. Users can now create tests that replicate the asynchronous behavior of the application. Database-Computed Default Values Django 5.0 lets you define database-computed default values. It means you get more powerful and accurate default settings. The new `Field.db_default` parameter enables users to set database-computed default values for model fields quickly. It is specifically helpful for time stamps or calculated fields. Although it is a minor change, it will have a substantial impact on the integrity of your data. Users can define default values using database functions. Features Deprecated in 5.0 Django 5.0 also has abolished a few old features. Therefore, you must check whether your code relies on any of them. If yes, you will need to update it accordingly. These features were depreciated in previous versions. Some notable ones include: Serialize test setting is no longer available. The undocumented django.utils.baseconv module is abolished. You can’t use undocumented django.utils.datetime_safe module anymore. The USE_TZ setting now has a default value of True. Earlier, it was false. Conclusion Django 5.0 introduces numerous updates and features that take the web development game to the next level. The platform has solidified its position as a powerful and versatile web framework. It has turned into a crucial tool for building websites and web applications. Enhanced flexibility in declaring field choices, improved performance, and numerous security features make it one of the best Python web frameworks. I’ve been working with Django since version 0.96 (2007), so if you need help with it, Contact Now
Ceph Persistent Storage for Kubernetes with Cephfs

Kubernetes is a prominent open-source orchestration platform. Individuals use it to deploy, manage, and scale applications. It is often challenging to manage stateful applications on this platform, especially those having heavy databases. Ceph is a robust distributed storage system that comes to the rescue. This open-source storage platform is known for its reliability, performance, and scalability. This blog post guides you on how to use Ceph persistent storage for Kubernetes with Cephfs. So let us learn the process step-by-step. Before we jump into the steps, you must have an external Ceph cluster. We assume you have a Ceph storage cluster deployed with Ceph Deploy or manually. Step 1: Deployment of Cephfs Provisioner on Kubernetes Deployment of Cephfs Provisioner on Kubernetes is a straightforward process. Simply log into your Kubernetes cluster and make a manifest file to deploy the RBD provisioner. It is an external dynamic provisioner that is compatible with Kubernetes 1.5+. vim cephfs-provisioner.yml Include the following content within the file. Remember, our deployment relies on RBAC (Role-Based Access Control). Therefore, we will establish the cluster role and bindings before making the service account and deploying the Cephs provisioner. — kind: Namespace apiVersion: v1 metadata: name: cephfs — kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cephfs-provisioner namespace: cephfs rules: – apiGroups: [""] resources: ["persistentvolumes"] verbs: ["get", "list", "watch", "create", "delete"] – apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "update"] – apiGroups: ["storage.k8s.io"] resources: ["storageclasses"] verbs: ["get", "list", "watch"] – apiGroups: [""] resources: ["events"] verbs: ["create", "update", "patch"] – apiGroups: [""] resources: ["services"] resourceNames: ["kube-dns","coredns"] verbs: ["list", "get"] — kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: cephfs-provisioner namespace: cephfs subjects: – kind: ServiceAccount name: cephfs-provisioner namespace: cephfs roleRef: kind: ClusterRole name: cephfs-provisioner apiGroup: rbac.authorization.k8s.io — apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: cephfs-provisioner namespace: cephfs rules: – apiGroups: [""] resources: ["secrets"] verbs: ["create", "get", "delete"] – apiGroups: [""] resources: ["endpoints"] verbs: ["get", "list", "watch", "create", "update", "patch"] — apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: cephfs-provisioner namespace: cephfs roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: cephfs-provisioner subjects: – kind: ServiceAccount name: cephfs-provisioner — apiVersion: v1 kind: ServiceAccount metadata: name: cephfs-provisioner namespace: cephfs — apiVersion: apps/v1 kind: Deployment metadata: name: cephfs-provisioner namespace: cephfs spec: replicas: 1 selector: matchLabels: app: cephfs-provisioner strategy: type: Recreate template: metadata: labels: app: cephfs-provisioner spec: containers: – name: cephfs-provisioner image: "quay.io/external_storage/cephfs-provisioner:latest" env: – name: PROVISIONER_NAME value: ceph.com/cephfs – name: PROVISIONER_SECRET_NAMESPACE value: cephfs command: – "/usr/local/bin/cephfs-provisioner" args: – "-id=cephfs-provisioner-1" serviceAccount: cephfs-provisioner Next, apply the manifest. $ kubectl apply -f cephfs-provisioner.yml namespace/cephfs created clusterrole.rbac.authorization.k8s.io/cephfs-provisioner created clusterrolebinding.rbac.authorization.k8s.io/cephfs-provisioner created role.rbac.authorization.k8s.io/cephfs-provisioner created rolebinding.rbac.authorization.k8s.io/cephfs-provisioner created serviceaccount/cephfs-provisioner created deployment.apps/cephfs-provisioner created Make sure that the Cephfs volume provisioner pod is in the operational state. $ kubectl get pods -l app=cephfs-provisioner -n cephfs NAME READY STATUS RESTARTS AGE cephfs-provisioner-7b77478cb8-7nnxs 1/1 Running 0 84s Step 2: Obtain the Ceph Admin Key and Create a Secret on Kubernetes Access your Ceph cluster and retrieve the admin key to be used by the RBD provisioner. sudo ceph auth get-key client.admin Save the value of the admin user key displayed by the above command. Later, we will incorporate this key as a secret in Kubernetes. kubectl create secret generic ceph-admin-secret \ –from-literal=key='<key-value>' \ –namespace=cephfs Where <key-value> is your Ceph admin key. Verify the creation by using the following command. $ kubectl get secrets ceph-admin-secret -n cephfs NAME TYPE DATA AGE ceph-admin-secret Opaque 1 6s Step 3: Make Ceph Pools for Kubernetes and Client Key To run a Ceph file system, you will need at least two RADOS pools, one for data and another for metadata. Usually, the metadata pool contains only a few gigabytes of data. Generally, individuals use 64 or 128 for large clusters. Therefore, we recommend a small PG count. Now let us make Ceph OSD pools for Kubernetes: sudo ceph osd pool create cephfs_data 128 128 sudo ceph osd pool create cephfs_metadata 64 64 Create a Ceph file system on the pools. sudo ceph fs new cephfs cephfs_metadata cephfs_data Confirm Ceph File System Creation. $ sudo ceph fs ls name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ] UI Dashboard Confirmation Step 4: Make Cephfs Storage Class on Kubernetes A StorageClass serves as a means to define the “classes” of storage you offer in Kubernetes. Let’s create a storage class known as “Cephrfs.” vim cephfs-sc.yml Add the following content to the file: — kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: cephfs namespace: cephfs provisioner: ceph.com/cephfs parameters: monitors: 10.10.10.11:6789,10.10.10.12:6789,10.10.10.13:6789 adminId: admin adminSecretName: ceph-admin-secret adminSecretNamespace: cephfs claimRoot: /pvc-volumes Where: ⦁ Cephfs is the name of the StorageClass to be created. ⦁ 10.10.10.11, 10.10.10.12 & 10.10.10.13 are the IP addresses of Ceph Monitors. You can list them with the command: $ sudo ceph -s cluster: id: 7795990b-7c8c-43f4-b648-d284ef2a0aba health: HEALTH_OK services: mon: 3 daemons, quorum cephmon01,cephmon02,cephmon03 (age 32h) mgr: cephmon01(active, since 30h), standbys: cephmon02 mds: cephfs:1 {0=cephmon01=up:active} 1 up:standby osd: 9 osds: 9 up (since 32h), 9 in (since 32h) rgw: 3 daemons active (cephmon01, cephmon02, cephmon03) data: pools: 8 pools, 618 pgs objects: 250 objects, 76 KiB usage: 9.6 GiB used, 2.6 TiB / 2.6 TiB avail pgs: 618 active+clean Once you have updated the file with the accurate value of Ceph monitors, give the Kubectl command to make the StorageClass. $ kubectl apply -f cephfs-sc.yml storageclass.storage.k8s.io/cephfs created Next, list all the available storage classes: $ kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE ceph-rbd ceph.com/rbd Delete Immediate false 25h cephfs ceph.com/cephfs Delete Immediate false 2m23s Step 5: Do Testing and Create Pod Create a test persistent volume claim to ensure that everything is smooth. $ vim cephfs-claim.yml — kind: PersistentVolumeClaim apiVersion: v1 metadata: name: cephfs-claim1 spec: accessModes: – ReadWriteOnce storageClassName: cephfs resources: requests: storage: 1Gi Apply manifest file $ kubectl apply -f cephfs-claim.yml persistentvolumeclaim/cephfs-claim1 created The successful binding will show the bound status. $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE ceph-rbd-claim1 Bound pvc-c6f4399d-43cf-4fc1-ba14-cc22f5c85304 1Gi RWO ceph-rbd 25h cephfs-claim1 Bound pvc-1bfa81b6-2c0b-47fa-9656-92dc52f69c52 1Gi RWO cephfs 87s Next, we can launch a test pod using the claim we made. First, create a file to store that data: vim cephfs-test-pod.yaml Add content
How to choose the right NodeJS Framework

It’s a modern world full of real-time web applications whether we talk about online games or messengers. Well, most modern applications have Node.js under the hood offering a scalable JavaScript environment. A Node.js framework features built-in resources including routing, templating, and database connectivity. Whether you’re using an MVC, Full-Stack MVC, or REST API, all the Node.js frameworks promote efficient and productive development. So, it’s finally a question, how to choose the right Node.js framework in 2023? You asked for it and here we brought a complete guide to help you make the right decision. Before you pick a framework, let’s start with exploring the best options you have online. 6 Best Options in NodeJS Frameworks to Choose From Express.js When it comes to choosing a Node.js framework, Express.js might be the top preference of most users. That’s because of its popularity, MVC architecture, and supreme capabilities of client-server interaction. Thanks to its simple code structure, Express.js offers a great user experience making it the perfect choice for small and medium-sized web app development. Also, it becomes an ideal choice if your project demands routing, middleware, and templating support. Nest.js Nest.js is trailing Express.js as one of the most efficient Node.js frameworks in the industry. Especially if you’re looking to build complex yet efficient server-side applications, Nest.js got the drill. The credit goes to its support for object-oriented programming (OOP) and reactive programming. As it supports TypeScript and JavaScript, you can easily integrate Nest.js with Express.js and build multi-layered applications. Koa.js Developed by Express.js developers, Koa.js is a masterpiece framework with lighter interface and cascading middleware. What it does?… The cascading middleware allows you to personalize your webpage content for different users without compromising the user experience. Additionally, you get access to various plugins and libraries of Express.js with lower complexity. It means Koa.js can be a pick for you if you are more into customizations and maintainability. Feathers.js Feathers.js is another excellent option for Node.js frameworks, particularly if you’re aiming to build real-time applications. With its focus on simplicity and flexibility, Feathers.js enables you to create scalable and efficient server-side applications effortlessly. It also offers support for various databases, making it a versatile choice for handling different types of projects. If you prioritize real-time functionalities, Feathers.js might be the ideal fit for your needs. Hapi.js Hapi.js is a robust and extensible Node.js framework designed for building APIs. With a strong emphasis on configuration over code, Hapi.js makes it easier to develop well-organized and maintainable applications. It excels in providing security features and allows you to control request handling, making it suitable for large-scale projects with specific security requirements. Hapi.js is also a great option for teams that value code consistency and readability. Sails.js For developers seeking a full-featured and opinionated framework, Sails.js is worth considering. It follows the convention-over-configuration principle, which means you spend less time configuring and more time coding. Sails.js offers an integrated ORM (Object-Relational Mapping) and supports real-time updates, making it a solid choice for building data-intensive applications like chat applications or social networks. If you prefer rapid development with batteries included, Sails.js could be your framework of choice. Top 5 Tips to Choose the Right NodeJS Framework: Project Requirements When embarking on the journey of choosing a NodeJS framework, your project’s unique requirements should be the guiding light. Each application comes with its own set of challenges and goals, and understanding them is paramount. Whether you need real-time capabilities, robust data processing, or server-side rendering, tailoring your choice to match these needs ensures a harmonious development process and a successful end product. By thoroughly analyzing your project’s necessities, you can avoid the pitfalls of selecting an ill-fitting framework, saving time, effort, and resources. Easy to Learn and Use Simplicity and accessibility are virtues in the world of software development, and when it comes to choosing a NodeJS framework, ease of learning and usage become decisive factors. An intuitive framework with clear documentation, comprehensive tutorials, and a supportive community fosters a welcoming environment for developers of all levels of expertise. Learning curves can be reduced significantly, and teams can quickly adapt and become productive with a framework that offers well-designed interfaces and conventions. Smooth onboarding processes and streamlined workflows empower developers to focus on actual problem-solving rather than wrestling with complex setups and configurations. Scalability In the realm of modern web applications, scalability is the bedrock of sustainable success. When selecting a NodeJS framework, it is essential to consider its ability to scale effortlessly. A framework that can handle increased user loads and growing data volumes without sacrificing performance is an invaluable asset. Horizontal scaling, the ability to distribute the application across multiple servers, and efficient utilization of multi-core processors are crucial characteristics of a scalable framework. By choosing a framework that can grow with your application’s demands, you ensure a seamless user experience, better resource management, and future-proofing your project. Versions Upgrade The landscape of NodeJS development is ever-evolving, with new versions constantly being released, each bringing improvements, security fixes, and exciting features. When evaluating NodeJS frameworks, it is imperative to consider how well-maintained and updated they are to keep pace with the latest NodeJS releases. Additionally, it minimizes the risk of compatibility issues and security vulnerabilities. Being on the cutting edge of the NodeJS ecosystem translates to a more future-proof and efficient application, giving you a competitive advantage. Community Support The value of a strong and engaged community cannot be overstated when selecting a NodeJS framework. A vibrant community signifies the framework’s reliability, popularity, and potential for long-term viability. When you encounter challenges or have questions during the development process, a robust community can provide invaluable assistance, shared knowledge, and innovative solutions. Community support often comes in the form of online forums, chat groups, documentation contributions, and open-source collaborations. Conclusion: In conclusion, choosing the right Node.js framework for your project is a crucial decision that can significantly impact its success. The six frameworks discussed in this guide and each have their unique strengths and
Angular v16 — An Ultimate Game Changer
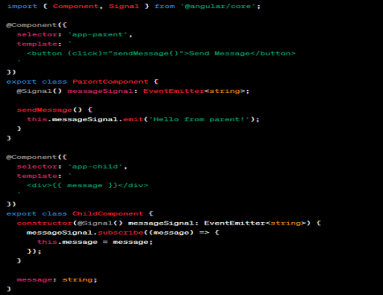
Angular, the popular JavaScript framework, has been continuously evolving to meet the demands of modern web development. With each major release, Angular brings new features, enhancements, and optimizations. Angular v16 is no exception, and it introduces several groundbreaking changes that make it an ultimate game changer for developers. In this article, we will explore the top new inclusions and exclusions in Angular v16 and discuss how they revolutionize the development experience. So, let’s get started! What’s New in Angular v16? — Top New Inclusions and Exclusions Binding router Information to Component Inputs First and foremost, Angular v16 allows you to bind router information to component inputs to eliminate boilerplate code during development. You can access the router data including resolved router data, params, and queryParams without using ActivatedRoute. That’s because this new feature gets the router data available as input in the component itself. So, you can use those inputs to fetch the values instead of messing up with ActivatedRoute. Here’s an example: // Current approach, which would still work @Component({ … }) class SomeComponent { route = inject(ActivatedRoute); data = this.route.snapshot.data['dataKey']; params = this.route.snapshot.params['paramKey'] } //New approach @Component({ … }) class SomeComponent { @Input() dataKey: string; @Input() paramKey: string; //or @Input() set dataKey(value: string){ //react to the value }; @Input() set paramKey(value: string){ //react to the value }; } Angular Signals Angular Signals is a new feature in Angular v16 that enables the communication between components using a publish-subscribe pattern. It allows components to emit signals and subscribe to signals emitted by other components. This feature promotes loose coupling and makes it easier to build modular and reusable components. import { Component, Signal } from '@angular/core'; @component ({ selector:'app-parent', template: ' <button (click)="sendieszage()*>Send Mezzage</button>' }) export class Parentcoponent { @Signa1() messagesignal: Eventemstter<string>; sendMessage() { this.messageSignal.emit('Hello from parent!'); } } @Component({ semprater: 'app-child', template: ' <div>{{ message }} </div>' }) export class ChildComponent { constructon(@signal() messageSignal: EventEmitter<string>){ messageSignal.subscribe((message) => { this: message = message; }); } message: string; } In this example, the `ParentComponent` emits a signal when the button is clicked, and the `ChildComponent` subscribes to that signal and displays the message. RxJS Interoperability Angular v16 brings improved interoperability with RxJS, making it easier to work with observables and leverage the power of reactive programming. The new `@rxjs` package provides decorators and utilities for integrating RxJS into Angular components seamlessly. For instance, you can use the `@rxjs/debounceTime` decorator to debounce user input in an Angular component: import { Component } from '@angular/core'; import { debounce } from '@rxjs/debounceTime'; @component ({ selector:'app-example', template: ' <input (input)="handleInput($event.target.value)"/>' }) export class ExampleComponent { @debounceTime(300) handleInput(value: string){ // Perform operations with debounced value } } The `@rxjs/debounceTime` decorator automatically applies the `debounceTime` operator to the `handleInput` method, simplifying the usage of RxJS operators within Angular components. DestroyRef Managing subscriptions and resources in Angular components can be a challenge. Angular v16 introduces the `DestroyRef` interface, which simplifies the cleanup process when a component is destroyed. By implementing the `DestroyRef` interface, you can automatically unsubscribe from subscriptions and perform cleanup tasks when the component is destroyed: import { Component, OnInit, OnDestroy } from '@angular/core'; import { Subscription } from '@rxjs'; import { DestroyReg } from '@angular/destroy-ref'; @Component ({ selector:'app-example', template: ' <p>Example Component</p>' }) export class ExampleComponent implements OnInit, OnDestroy, DestroyReg { private subscription: Subscription; ngOnInit(){ this.subscription = /* … */; // Initialize subscription } ngOnDestroy(){ this.ngOnDestroy(); } } The `DestroyRef` interface ensures that the `onDestroy` method is called automatically when the component is destroyed, reducing the risk of memory leaks and resource wastage. Non-Destruction Hydration Angular v16 introduces non-destruction hydration, a feature that improves the performance of hydration during server-side rendering (SSR). In previous versions, Angular would destroy and recreate components during hydration, which could be costly in terms of performance. With non-destruction hydration, Angular now preserves the existing component instances during hydration, enhancing SSR performance. This change significantly reduces the overhead of rendering on the server and improves the overall user experience import { Component, NgModule } from '@angular/core'; import { BrowserModule, TransferState } from '@angular/platform-browser'; @Component ({ selector:'app-root', template: ' <h1>{{ title }}</h1> <p>{{ content }}</p>' }) export class AppComponent { title: string; content: string; constructor(private transferDtate: TransferState) { // Retrieve data from server-side Iendering const data = this.transferState.get<any>('pageData', {}); this.title = data.title; this.content = data.content; } } @NgModule({ declarations: [AppComponent], imports: [BrowserModule.widthServerTransition({ appId: 'my-app'})], providers: [TransferState], bootstrap: [AppComponent] }) export class AppModule {} In this example, we have an AppComponent that displays a title and content. During server-side rendering, the data is transferred using TransferState and stored in the state. When the Angular application is initialized on the client side, the AppComponent constructor retrieves the data from TransferState and assigns it to the component properties. This way, the component is hydrated without destroying and recreating it, improving the performance of server-side rendering. CSP Support for inline-styles Content Security Policy (CSP) is an important security mechanism to protect web applications against cross-site scripting (XSS) attacks. In Angular v16, inline styles are now compatible with CSP restrictions. This means that you can safely use inline styles within your Angular templates while adhering to CSP rules. The Angular compiler in v16 generates the necessary hashes for inline styles, ensuring they are safely executed within the CSP policy. This change provides more flexibility for developers to style their components without compromising security. Exclusion of ngcc In previous versions of Angular, the ngcc (Angular Compatibility Compiler) was used to compile and transform third-party libraries to be compatible with the Angular Ivy compiler. However, Angular v16 removes the need for ngcc altogether. With the advancements in Ivy and the ecosystem’s migration to Ivy-compatible libraries, ngcc is no longer required. This simplifies the build process and improves the overall build performance, making Angular projects faster to compile and deploy. Esbuild dev server Angular v16 introduces a new dev server powered by Esbuild, a fast JavaScript bundler. The Esbuild dev server significantly reduces the startup time of Angular applications during development. It achieves this by leveraging the speed
Django vs Flask — Which Python Framework is Perfect for Your Web Development Process?

When it comes to web development in Python, two prominent frameworks stand out: Django and Flask. These frameworks offer developers a robust foundation to build powerful web applications efficiently. Based on Model-View-Controller (MVC) architectural pattern, Django is favored for large-scale, complex projects. On the other hand, Flask is a microframework offering a lightweight and flexible approach, empowering developers to have greater control over the application structure. Both platforms have exclusive capabilities and drawbacks complicating the decision-making. In this article, we’ll delve into the technical aspects and industrial attributes of Django and Flask to help you make an informed decision for your web development endeavors. So, let’s get started! Django — Self-Sufficient Web Framework From the house of the Django Software Foundation, Django is a robust and scalable web framework known for its “batteries-included” philosophy. With built-in features and packages, Django promotes rapid development by minimizing the need for external dependencies. Its core components include an Object-Relational Mapping (ORM) layer, a template engine, form handling, authentication, and authorization. Django’s ORM simplifies database interactions, allowing seamless integration with various database systems. The framework follows the Model-View-Controller (MVC) architectural pattern, providing a clear separation of concerns. Additionally, the admin interface offers an out-of-the-box solution for managing application data, making it a popular choice for content-heavy websites. Flask — Minimalistic Microframework Flask is a lightweight and flexible micro-framework designed for simplicity and minimalism. Developed by Armin Ronacher, it provides a solid foundation for web development, offering developers greater control over the application structure. It follows a “micro” philosophy, providing essential tools and leaving the choice of additional libraries to the developers. Furthermore, the framework leverages the Werkzeug toolkit for handling routing and the Jinja2 template engine for rendering dynamic content. Its flexibility and scalability make Flask an excellent choice for small to medium-sized projects, RESTful APIs, and microservices. In addition to its features, the active community and extensive documentation ensure continuous support and updates, contributing to its widespread adoption. Comparison of Django and Flask Based on Industrial Attributes Development Capabilities Django’s batteries-included approach provides a wide array of built-in features, making development faster and more efficient. Its robust ORM simplifies database interactions, while the template engine streamlines UI development. Besides, Flask offers greater flexibility allowing developers to choose and integrate only the necessary components. This makes Flask ideal for lightweight and highly customizable applications. So, Django’s extensive feature set makes it better suited for complex projects that require rapid development and adherence to best practices. If you’re working on smaller projects that require fine-grained control over the application structure, Flask can be a great choice. Scalability Django’s scalability is what makes it a perfect choice for large-scale applications. With its ability to handle heavy workloads, Django’s robust architecture and efficient request handling ensure optimal performance. On the other hand, Flask is inherently scalable, allowing developers to add or remove components as needed. It features a modular design and customizable nature that enables developers to optimize performance for specific use cases. Architecture As discussed above, Django follows the Model-View-Controller (MVC) architectural pattern. This promotes code organization and maintainability, making it easier for multiple developers to collaborate on a project. By default, Flask works with the MVT pattern and offers a similar structure but with a more flexible design. Developers have more freedom to choose how to structure their projects and interact with components. Components and Reutilization Django is famous for its comprehensive set of built-in components, such as the ORM, template engine, and authentication system. As it reduces external dependencies, this promotes code reusability and reduces development time. While Flask provides greater flexibility, it still requires developers to rely on external packages for specific functionality. Flask’s modular design facilitates component reusability, enabling developers to build custom solutions tailored to their project requirements. Community and Support Django boasts a large and active community, with numerous contributors and a wealth of resources available. The community-driven nature of Django ensures continuous development, frequent updates, and comprehensive documentation. This support system provides assistance, encourages best practices, and addresses issues promptly. Flask also enjoys an active community, although smaller in comparison to Django. However, Flask’s community thrives on its simplicity and flexibility, offering extensive documentation and a range of community-contributed extensions. While Django’s larger community offers broader support, Flask’s community provides a close-knit environment for developers seeking minimalistic solutions. Establishment and Updates With its long history, Django has established itself as a mature and stable framework, trusted by many large-scale projects and enterprises. Its consistent updates, bug fixes, and security patches ensure reliability and compatibility with the latest technologies. Despite being a younger framework, Flask has also gained substantial popularity and has seen regular updates, although at a relatively smaller scale. Flask’s updates focus on maintaining stability and introducing new features based on community feedback. Testing Django provides a robust testing framework as part of its core, enabling developers to write comprehensive tests for their applications. Its testing utilities simplify unit testing, integration testing, and user interaction testing. Flask, being a microframework, does not include a built-in testing framework. However, Flask integrates seamlessly with popular Python testing libraries such as pytest and unittest, offering flexibility in choosing the desired testing approach. Both frameworks promote test-driven development and provide the necessary tools and extensions for efficient and thorough testing. End of the Line In conclusion, the choice between Django and Flask ultimately depends on the specific requirements and goals of your web development project. Django’s batteries-included approach, mature ecosystem, and adherence to MVC architecture make it an excellent choice for large-scale, complex applications On the other hand, Flask’s lightweight and flexible nature, coupled with its simplicity and customizability, make it ideal for smaller projects, RESTful APIs, and microservices. It empowers developers to have fine-grained control over the application structure and offers the freedom to choose and integrate only the necessary components. Consider your project’s scale, complexity, customization needs, and community support when making your decision, ensuring the best fit for your web development process.
How the New TypeScript 4.9+ Streamlines the Type Safety in Storybook 7.0?
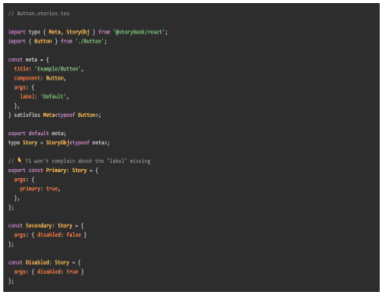
TypeScript is popularly used for JavaScript extension and data specification in the industry. As it reports unmatched types, writing in TypeScript can ensure productivity and optimal developer experience while coding. If we are onto using TypeScript, Storybook 7.0 is worth mentioning. That’s because it allows you to write in TypeScript without any configuration setup and boost your experience with built-in APIs. With the launch of Storybook 7.0, the tool rectified all the pain points in the previous version. Now, you get a combination of CSF 3 and the new TypeScript 4.9+ operator to bolster accuracy and safety. Read on to explore how this combination can make your coding more productive and safer while using the latest Storybook 7.0. Storybook 7.0 — An Introduction to Update 8/18 Storybook 7.0 or update 8/18 is a core upgrade of Storybook focused on better interaction testing and user experience. You get 3.5% more screen space for Canvas with over 196 icons available for complete customizations. By the same token, Storybook 7.0 is more compatible in integrating with Remix, Qwik, and SolidJS. The also features some documentation upgrades such as MDX 2 and simplified import of stories. Lastly, the most exclusive upgrade is the combination of TypeScript 4.9+ and CSF3. Let’s see what makes it a big highlight! What is TypeScript 4.9+? TypeScript 4.9+ is a statically-typed superset of JavaScript that provides additional features such as type annotations, interfaces, and generics. It enables developers to write more maintainable and scalable code by catching potential errors at compile-time rather than runtime. One of the key benefits of using TypeScript with Storybook 7.0 is that it allows developers to specify the expected types of props and events for each component. This ensures that any components that use these props and events are properly typed and provide a clear contract for how they should be used. In addition to these benefits, TypeScript can also improve the documentation and discoverability of UI components in Storybook 7.0. By leveraging TypeScript’s support for JSDoc annotations, developers can document the expected usage of each component and generate API documentation automatically. Look at the difference between TypeScript types in Storybook 6 and Storybook 7.0 below. Combination of CSF3 Syntax and TypeScript 4.9+ In addition to TypeScript 4.9+, the Component Story Format (CSF) also received an upgrade from version CSF 2 to CSF3. The combination of both offer enhanced type safety, better in-editor type checking, and Codemod for easy upgrades. Here are the top elements of this incredible combination! StoryObj Type With the upgrade CSF3, you now get access to the StoryObj type that manipulates stories as objects and infers the type of component props. The feature was still there but the previous story was not so powerful to automatically infer prop types. On the other hand, this new syntax depreciates React-Specific ComponentMeta and ComponentStory using React, Vue, Svelte, and Angular. Check the result with a side-by-side comparison of CSF2 and CSF3 given below satisfies Operator satisfies Operator is the most useful feature of TypeScript 4.9+ for strict type checking. Pair CSF3 with satisfies operator to better type safety and fix unspecified/specified issues. Take a look at the below example where TypeScript is not raising any issue for unspecified label arg. If you use satisfies operator, you can fix that issue as we did below. // Button.stories.tsx import type { Meta, StoryObj } from '@storybook/react'; import { Button } from './Button'; const meta = { title: 'Example/Button', component: Button, } satisfies Meta<typeof Button>; export default meta; type Story = StoryObj<typeof meta>; export const Primary: Story = { args: { primary: true, }, }; After fixing the issue, you can expect TypeScript to provide an error for unspecified arg. Auto-infer Component Level args Pairing the CSF and TypeScript is good but it will not infer the types automatically unless you specify the connection. In this scenario, TypeScript will show errors on the stories even if you have provided a label in meta-level args. That’s where auto-infer component level args come up to specify the connection between CSF and TypeScript. To make them understand the connection, you need to pass the typeof meta to StoryObj at both story and meta-level. Here’s how you can do it! // Button.stories.tsx import type { Meta, StoryObj } from '@storybook/react'; import { Button } from './Button'; const meta = { title: 'Example/Button', component: Button, args: { label: 'Default', }, } satisfies Meta<typeof Button>; export default meta; type Story = StoryObj<typeof meta>; // ???? TS won't complain about the "label" missing export const Primary: Story = { args: { primary: true, }, }; const Secondary: Story = { args: { disabled: false } }; const Disabled: Story = { args: { disabled: true } }; Vue As discussed above, Storybook 7.0 is more compatible with modern frameworks. Vue is the best example of that but you need to set up an ideal environment. Look for SFC files with vue-tsc and access the editor support in VSCode. Take a look at the Vue3 single file component. <script setup lang="ts"> defineProps<{ count: number, disabled: boolean }>() const emit = defineEmits<{ (e: 'increaseBy', amount: number): void; (e: 'decreaseBy', amount: number): void; }>(); </script> <template> <div class="card"> {{ count }} <button @click="emit('increaseBy', 1)" :disabled='disabled'> Increase by 1 </button> <button @click="$emit('decreaseBy', 1)" :disabled='disabled'> Decrease by 1 </button> </div> </template> Svelte Like Vue, Svelte features excellent support for TypeScript and enables .svelte files. You can utilize svelte-check and add VSCode editor support to run type checks. Consider the following component as an example. <script lang="ts"> import { createEventDispatcher } from 'svelte'; export let count: number; export let disabled: boolean; const dispatch = createEventDispatcher(); </script> <div class="card"> {count} <button on:click={() => dispatch('increaseBy', 1)} {disabled}> Increase by 1 </button> <button on:click={() => dispatch('decreaseBy', 1)} {disabled}> Decrease by 1 </button> </div> Conclusion: Conclusively, the new TypeScript 4.9+ features in Storybook 7.0 have greatly improved the type safety and developer experience for creating UI components. With the addition of advanced type inference capabilities, developers can now create reusable components with
Kubernetes Persistent Volumes — 5 Detailed Steps to Create PVs
If you want to persist data in Kubernetes, you may utilize the readable and writable disk space available in Pods as a convenient option. But one thing you must know is that the disk space depends on the lifecycle of Pod. Unsurprisingly, your application development process features independent storage available for every node and can handle cluster crashes. Kubernetes Persistent Volumes got your back with their independent lifecycle and great compatibility for stateful applications. This article will lead you to 5 extensive steps to create and implement persistent volumes in your cluster. Before that, let’s dig down to know what exactly persistent volumes in Kubernetes are along with some important terms! Persistent Volumes in Kubernetes A Kubernetes Persistent Volume is a provisioned storage in a cluster and works as a cluster resource. It’s a volume plugin for Kubernetes with an independent lifecycle and no dependency on the existence of a particular pod. Unlike containers, you can read, write and manage your databases without worrying about disk crashes because of restart or termination of the pod. As a shared unit, all the containers in a pod can access the PV and can restore the database even if an individual container crashes. Here are some important terms you must know! Access Modes The accessModes represent the nodes and pods that can access the volume. The field ReadWriteOnce defines every pod having access to read and write the data in a single mode. If you’re using Kubernetes v1.22, you can read or write access on a single node using ReadWriteOncePod. Volume Mode The volumeMode field is mounting functionality of volume into the pods based on a pre-set directory. It defines the behaviour of volume in each Filesystem of a pod. Alternatively, you can use a volume as a raw block storage without any configuration with a Block field. Storage Classes As the name describes, storage classes are the different storage types you can use according to the hosting environment of your cluster. For instance, you can choose azurefile-csi for Microsoft Azure Kubernetes (AKS) clusters while do-block-storage is great for DigitalOcean Managed Kubernetes. Creating a Persistent Volume Step 1: YAML file The process of creating Kubernetes persistent volumes starts with creating a YAML file. The storage configuration represents a simple persistent volume of 1 Gi capacity. Here’s how you can create a YAML file for your PV in Kubernetes: apiVersion: v1 kind: PersistentVolume metadata: name: example-pv spec: accessModes: ReadWriteOnce capacity: storage: 1Gi storageClassName: standard volumeMode: Filesystem Step 2: Adding Volume to the Cluster Once you have created the Persistent Volume, you can add your new persistent volume to your cluster. We recommend using Kubectl for this to make it easier. To add new persistent volume, run: $ kubectl apply -f pv.yaml If you see the following error message while running the command, The PersistentVolume "example-pv" is invalid: spec: Required value: must specify a volume type Try using dynamic volume creation which will automatically create a persistent volume whenever it’s used. That’s because the cloud providers usually restrict allocating inactive storage in the cluster and dynamic volume can be your good-to-go option. Step 3: Linking Volumes to Pods Linking PVs with the pods requires the request to read/write files in a volume. Here the Persistent Volume Claim (PVC) can get you access to the example-pv volume. Let’s see how an example volume claim looks like! apiVersion: v1 kind: PersistentVolumeClaim metadata: name: example-pvc spec: storageClassName: "" volumeName: example-pv As discussed above, you may need dynamic volume creation in some scenarios. You can request a claim for that in the way mentioned below. apiVersion: v1 kind: PersistentVolumeClaim metadata: name: example-pvc spec: accessModes: – ReadWriteOnce resources: requests: storage: 1Gi storageClassName: standard Now, you have unlocked accessModes and storageClassName fields after the claim. All you need to do is to apply the claim to your cluster using Kubectl. Run the following command to quickly apply the claim to your cluster. $ kubectl apply -f pvc.yaml persistentvolumeclaim/example-pvc created In the last, use the volumes and volumeMount fields to link the claim to your pods. This will add pv to your containers section of the manifest and make the files overlive the container instances. To link the claim, run: apiVersion: v1 kind: Pod metadata: name: pod-with-pvc spec: containers: name: pvc-container image: nginx:latest volumeMounts: – mountPath: /pv-mount name: pv volumes: – name: pv persistentVolumeClaim: claimName: example-pvc Step 4: Demonstrating Persistence In the demonstration, you can verify the behaviour of PV in different scenarios. Let’s take a quick example for better understanding. Get a shell to the pod: $ kubectl exec –stdin –tty pod-with-pvc — sh Write a file to the /pv-mount directory mounted to: $ echo "This file is persisted" > /pv-mount/demo Detach the file from the container: $ exit Delete the pod using kubectl: $ kubectl delete pods/pod-with-pvc pod "pod-with-pvc" deleted Recreate the pod: $ kubectl apply -f pvc-pod.yaml pod/pod-with-pvc created Get a shell to the container and read the file: $ kubectl exec –stdin –tty pod-with-pvc — sh $ cat /pv-mount/demo This file is persisted Step 5: Managing Persistent Volumes Kubectl allows you to manage your Kubernetes Persistent Volumes whether you want to retrieve a list or remove a volume. To retrieve a list of PVs, run: $ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-f90a46bd-fac0-4cb5-b020-18b3e74dd3b6 1Gi RWO Delete Bound pv-demo/example-pvc do-block-storage 7m52s Review persistent volume claims: $ kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE example-pvc Bound pvc-f90a46bd-fac0-4cb5-b020-18b3e74dd3b6 1Gi RWO do-block-storage 9m Sometimes, a volume or PV claim may show a Pending status as the storage class is yet to provision storage. But you can check what’s slowing down the claim process in object’s event history with describe command. $ kubectl describe pvc example-pvc … Events: Type Reason Age From Message —- —— —- —- ——- Normal Provisioning 9m30s dobs.csi.digitalocean.com_master_68ea6d30-36fe-4f9f-9161-0db299cb0a9c External provisioner is provisioning volume for claim "pv-demo/example-pvc" Normal ProvisioningSucceeded 9m24s dobs.csi.digitalocean.com_master_68ea6d30-36fe-4f9f-9161-0db299cb0a9c Successfully provisioned volume pvc-f90a46bd-fac0-4cb5-b020-18b3e74dd3b6 Conclusion: By combining Kubernetes and Persistent Volumes, you can effectively and easily
Level Up Your React Skills — Top 6 React Design Patterns to Try

Introduction With its incredible capabilities, React has overlapped the old-school CSS, HTML, and JavaScript offering ease of coding. The JavaScript library works with virtual DOM concepts and an exclusive range of developer tools instead of just manipulating the DOM. Developers usually run out of ideas with new concepts and ideas while coding. If you’re one of those looking to revamp your React skills, you must utilize React Design Patterns. Let’s explore them all! 6 Most Useful React Design Patterns to Try Container Components First and foremost, the container components pattern leads the list with its elite diversification functionality. It’s designed to separate data fetching/logic and events from the presentational components. As the presentational components are dumb components, they just render the data fetched and passed by the container component. Take a look at the example displaying the container component pattern for a movie app using React hooks. import { useEffect, useState } from 'react'; import { movies } from '../data/movies'; import './movies.css'; const fetchMovies = () => { return movies; }; const MovieContainer = () => { console.log(fetchMovies()); const [movies, setMovies] = useState([]); useEffect(() => { const movies = fetchMovies(); console.log('MovieContainer: useEffect: movies: ', movies); setMovies(movies); }, []); return( <div className="movie-container"> <h2>Movies</h2> <ul className ="movie-list"> {movies.map(movie => ( <li key={movie.id} className="movie"> <img src={movie.poster} alt={movie.title} /> <p>{movie.title} by {movie.director} was released on {movie.year}</p> <p>Rating: {movie.rating}</p> </li> ))} </ul> </div> ); }; export default MovieContainer; Render Props In addition to conditional components, using render props can also be a great bet if you experience logic repetition. This pattern works with Prop which is equal to a function allowing you to share code between React components. With render props, you can enable a component to toggle visibility and render its content. Take a look at the below example for an expansive view! function Toggle({ children }) { const [isVisible, setIsVisible] = useState(false); function handleClick() { setIsVisible(!isVisible); } return children({ isVisible, toggle: handleClick }); } Conditional Rendering Conditional rendering is an ultimate technique designed to render specific UI components according to certain factors such as user input, component state, and more. If you’re looking to implement a conditional rendering pattern in React, you can do it with the ternary operator, Logical && Operator, and switch statements. Here’s how you can do it! Ternary Operator import React from "react"; function Greeting () { const isLoggedin = 'true' return ( <div> {isLoggedin ? (<h1>Welcome back, User</h1>) : (<h1>please login to continue</h1>)} </div> ) } export default Greeting Logical && Operator function ExampleComponent(props) { const isLoggedIn = props.isLoggedIn; return ( <div> {isLoggedIn && <p>Welcome back, user!</p>} {!isLoggedIn && <p>Please login to continue.</p>} </div> ); } Switch Statements function ExampleComponent(props) { const status = props.status; switch (status) { case "loading": return <LoadingIndicator />; case "error": return <ErrorMessage message={props.errorMessage} />; case "success": return <SuccessMessage message={props.successMessage} />; default: return null; } } Context API If we just dig into the default functionalities, React is set to pass props through every level of the component tree to pass data to a child component. With Context API, you can pass data at any level of the component tree without passing the props. The process to use React Context API starts with creating a context object with the createContext function. After this, it will allow you to use the provider component to take value prop for any type of data. Let’s make it work! import React from 'react'; import ReactDOM from 'react-dom'; import MyContext from './MyContext'; function App() { const data = { name: 'John', age: 30 }; return ( <MyContext.Provider value={data}> <ChildComponent /> </MyContext.Provider> ); } function ChildComponent() { return ( <MyContext.Consumer> {value => ( <div> <p>Name: {value.name}</p> <p>Age: {value.age}</p> </div> )} </MyContext.Consumer> ); } ReactDOM.render(<App />, document.getElementById('root')); HOCs Higher Order Components (HOCs) are JavaScript functions designed to add data and functionality to the component. They enable the reuse of component logic and allow you to share standard functionality between multiple components. Moreover, the best part is the HOC pattern doesn’t require duplicating the code to add functionalities to components. Just create a Hoc.js file with the following code: import React from "react"; const Hoc = (WrappedComponent, entity) => { return class extends React.Component { state = { data: [], term: "", }; componentDidMount() { const fetchData = async () => { const res = await fetch( `https://jsonplaceholder.typicode.com/${entity}` ); const json = await res.json(); this.setState({ …this.state, data: json }); }; fetchData(); } render() { let { term, data } = this.state; let filteredData = data.slice(0, 10).filter((d) => { if (entity === "users") { const { name } = d; return name.indexOf(term) >= 0; } if (entity === "todos") { const { title } = d; return title.indexOf(term) >= 0; } }); return ( <div> <h2>Users List</h2> <div> <input type="text" value={term} onChange={(e) => this.setState({ …this.state, term: e.target.value }) } /> </div> <WrappedComponent data={filteredData}></WrappedComponent> </div> ); } }; }; export default Hoc; Hooks Lastly, you have React Hooks as the most appreciated React Design Patterns. The pattern was introduced with React 16.8 update to enable developers to use React without any classes. Interestingly, you get over 15 pre-built React hooks in the library including Effect Hook and State Hook. Even if you’re looking for a custom hook, you can create your own hook from scratch or just modify the existing one according to your needs. Here we get you an example of using the useState hook known for tracking state in a function component. import { useState } from 'react'; function Counter() { const [count, setCount] = useState(0); return ( <> <p>Count: {count}</p> <button onClick={() => setCount(count + 1)}> Increase </button> </> ); } Conclusion React has emerged as an essential part of today’s web development, offering versatile features that provide developers with an improved coding experience. However, it poses innate challenges while executing practical experiments. Solving these issues involves a great deal of attention and experimentation to understand modern design patterns and frameworks. Utilizing React Design Patterns is a great way to gain more insight into your projects and build cross-platform applications