
GitHub Actions: An In-depth Guide for Beginners

Actions Platform? It would not be wrong to mention that GitHub Actions has significantly transformed the workflow of web developers. This Continuous Integration and Continuous Delivery (CI/CD) platform enables them to build, test, and deploy web codes straight from GitHub. Are you a beginner? Do you want to learn how this tool can boost your productivity? Read this guide until the end. It makes you aware of the components and features of GitHub Actions. Let’s get started! What is GitHub GitHub Actions is an automated tool powered by GitHub. It supports the automation of software building, testing, and deployment within the repositories of GitHub. Since the user does not need to leave GitHub, it naturally enhances the workflow and productivity. Developers can perform repetitive tasks while reducing manual intervention. GitHub Actions utilizes a YAML file to outline different steps of a workflow. These steps include running a script, testing, deploying codes, and sending notifications. Components of GitHub Actions GitHub Actions is a powerful tool that makes web development smooth and quick. Wondering what mechanisms make GitHub Actions work so well? Let’s learn about them. Workflow A workflow is a programmed process that runs one or more jobs. This configurable process is defined by a YAML file in the .github/workflows directory in a repository. This repository can have several workflows. And each workflow can perform a different set of jobs. For instance, you can use one workflow to create and test pull requests while another to deploy your application. Events An event is a particular activity in a repository. It is like a trigger for workflows. When events occur within a repository, GitHub Actions respond to them. These events can push requests, pull requests, or other actions. Jobs Jobs are a set of steps in a workflow. They are executed under the same runner. Each step is either a shell script or an action. Scripts execute while actions run. Action An action is an application for the GitHub Actions. It performs frequently repeated tasks. The application helps web developers to reduce the number of repetitive codes they write in their workflow files. Runner A runner is a server that runs workflows when they are triggered. One runner can perform a single task at a time. Essential Features of GitHub Actions Though GitHub Actions offers various advantages to web developers, a few prominent features are below. Variable in Workflows The default GitHub actions environment variables, incorporated in every workflow, run automatically. However, users can customize the environment variables by setting them in their YAML files. In the following example, you can see how one can create custom variables for POSTGRES_HOST and POSTGRES_PORT. These variables are available in the node client.js script. jobs: demo-job: steps: – name: Connect to your PostgreSQL run: node client.js env: POSTGRES_HOST: postres POSTGRES_PORT: 5432 Addition of Scripts to Workflow GitHub Actions allow the addition of scripts to workflow. You can employ actions for running scripts and shell commands. They get executed on the selected runner. Find out how an action can use the run keyword to execute npm install –g bats on the runner in the flowing example. jobs: demo-job: steps: – run: npm install -g bats Sharing Data Between Jobs One of the crucial features of GitHub Actions is that you can reuse the jobs you created earlier. You can save files for later use as artifacts on GitHub. These files get generated while building and testing web code. These files could be screenshots, binary, test results, and package files. You can also make your file and upload it on artifacts for later use. jobs: demo-job: name: Save output steps: – shell: bash run: | expr 1+1 > output.log – name: Upload output file users: actions/upload-artifact@v3 with: name: output-log-file path: output.log Step-by-Step Creation of GitHub Action File If you want to learn the workings of the GtiHub actions workflows, here is the step-by-step guide. You will need a GitHub repository to create the GitHub actions. Set up of the GitHub Action File ⦁ Make a .github/workflows directory in your repository on GitHub in case it does not already exist. ⦁ In the directory, you may create a file name: GitHub-actions-demo.yml. ⦁ Next, copy the following YAML content into the GitHub-actions-demo.yml file. name: GitHub Actions Example on: [push] jobs: Explore-GitHub-Actions: runs-on: ubuntu-latest steps: run: echo " The job was automatically triggered by a ${{Github.event_name }} event." run: echo " This job is now running on a ${{ runner.os }} server hosted by GitHub!" run: echo " The name of your branch is ${{ GitHub.ref }} and your repository is ${{ GitHub.repository }}." name: Check out repository code user: actions/checkout@v3 run: echo " The ${{ GitHub.repository }} repository has been cloned to the runner." run: echo " The workflow is now ready to test your code on the runner." name: List files in the repository run: | Is ${{ GitHub.workspace }} run: echo " This job's status is ${{ job.status }}." ⦁ Create a new branch for this commit and begin a pull request. ⦁ To create a pull request, click Propose new file. ⦁ When you commit your workflow file to a branch within your repository, it initiates the push event and then executes your workflow. Run the Files Your next step should be running the file. ⦁ Visit github.com and go to the main page of the repository. ⦁ Beneath your repository name, click Actions. ⦁ On the left sidebar, hit the workflow you want ⦁ Under Jobs, click on the Explore-GitHub-Actions job. The above log shows the breakdown of each step carried out. You can expand these steps to view its details. Conclusion GitHub Actions is a robust automation tool that streamlines development workflows. Web developers can leverage its flexibility, automation, and integration within GitHub. In addition to this, the platform supports event-driven workflows. In this blog, we learned about components of GitHub Actions. Also, we came to know about its essential features. All-in-all, GitHub Actions is a versatile tool for developers that simplifies the
Astro 3.0: Everything You Need to Know about it

Astro is an open-source web framework that enables users to design fast, efficient, and high-performance websites. It released its new avatar on August 30, 2023, known as Astro 3.0. According to the team, it is several times faster and feature-rich than previous versions. In this post, we will take an in-depth look at the revolutionary features of Astro 3.0. Before that, let us have a quick look at an Astro overview. Overview of Astro This open-source web framework is used to design heavy websites, such as landing pages, blogs, technical documentation, etc. Launched in June 2021, this open-source project provides support to more than 10,000 users. Similar to platforms like Next.js, Nuxt.js, and SolidStart, Astro features single-file components. The framework comes with a wide range of features, including partial hydration, zero-config development, incremental static regeneration, and static site generation. Let’s find out how Astro 3.0 is different from the previous version. What is new with Astro 3.0? Astro 3.0 is becoming popular as a prominent web framework to support the View Transitions API. Furthermore, it provides functionality for new browser APIs. Astro 3.0 features several exciting features, such as image optimization, SSR enhancements, performant HTML output, faster rendering, and more. Get to know more about these features in detail below. Astro 3.0: Exploring the New Features and Enhancements Full support for View Transitions API One of the outstanding features of Astro 3.0 is its support for View Transitions API. This application programming interface allows developers to create seamless transitions between different website components. You can fade, persist, morph, and slide stateful elements across page navigation. Furthermore, it enables native browser transition effects between pages. Earlier, only single-page applications could do transitions. With Astro 3.0, native page transition is possible. This feature makes it easier for developers to enhance user experience. Now you can: Transform persistent elements from one page to another Fade content on and off Slide content on and off Persist regular UI across pages without a refresh. Image Optimization (stable) Astro 3.0 features stable image optimization. Like Next.js, it also has a built-in <image> component that manages everything about rendering images on the web. This new version of Astro allows developers to compress or resize images. It automatically minimizes the page load times. As a result, images load faster in the browsers of users. This built-in feature has a significant role in enhancing website speed and performance. You can follow the below steps to use image optimization in Astro 3.0. Configure astro assets in your astro.config.mjs. Import images from the relative path from the existing .astro file. Use the image’s src and other properties in the <img> tag. Some other worth describing updates about image optimization in Astro 3.0 include: Support for Vercel’s built-in image service. You can optimize images from CMS tools and remote workflows. Astro utilizes Sharp as the default optimization library Faster Rendering Performance Astro is renowned for its rendering performance. However, with version 3.0, it has taken one step further. Compared to Astro 2.9, this new version renders components about 30% faster. This significant performance improvement is due to the less amount of JavaScript transported to the client by improving the rendering path. The developing team at Astro removed as much superfluous code as possible. SSR Enhancements for Serverless Astro 3.0 has brought numerous improvements to Server Side Rendering (SSR) for serverless applications. SSR technique generates web pages on the server before transporting them to the clients. Astro 3.0 lets you create responsive and dynamic web applications using serverless functions. Therefore, you get new ways to connect to the hosting platforms. HMR Enhancements for JSX Updating code was a big challenge with previous versions. Fortunately, with Astro 3.0, you can update codes instantly without refreshing the entire page. The framework brings HMR enhancements to JSX components. As a result, developers see changes in real-time. Not only does it minimize the development time, but also speeds up the debugging process. Astro 3.0 provides fast refresh support to React and Preact users. They can make changes without the fear of losing the component’s state. In addition, it also supports the component hierarchy. Consequently, the application maintains its structure after code changes. Optimized Build Output Astro 3.0 comes up with several changes in optimized build outputs. This latest version naturally minifies HTML outputs, reducing the payload and improving the overall response time. In addition, the team at Astro has replaced the messy astro-xxxx class names with a specific HTML attribute. Conclusion Astro 3.0 improvements make this framework ideal for web developers looking to create user-friendly yet powerful websites. It puts more stress on developer experience, performance, and user satisfaction. With features like support for the View Transitions API, improved rendering performance, and Image Optimization, we can say that Astro 3.0 leaps forward in the web development world.
Bun 1.0: Unveiling the Ultimate Development Tool

Since its launch, Bun 1.0 has become the talk of town in the web development community. It is gaining popularity as an all-in-one tool for JavaScript and TypeScript development. If you haven’t used it yet and want to explore Bun 1.0 features, this post is for you. Before we jump into the Bun 1.0 features, let’s learn about it briefly. Overview of Bun and its Significance Bun is a renowned open-source bundler for JavaScript and TypeScript. Jarred Sumner is the key person behind the foundation of this JavaScript runtime. Unlike Node.js and Deno, the bundler uses JavaScriptCore as the JavaScript engine. Bun 1.0 was launched on September 8, 2023. It is a versatile tool to build, test, debug, and run JavaScript and TypeScript applications. Bun 1.0 is quite fast in comparison to Node.js and Deno. Let us uncover all the Bun 1.0 features one by one. Features of Bun 1.0 Universal Tool Bun 1.0 meets the requirements of both JavaScript and TypeScript developers. Whether you are working on a single-file project or developing a full-stack application, Bun provides an efficient development environment. Below are some features that make Bun 1.0 worth using: Bun supports quick command execution, thanks to npx. NPX is part of Bun. It eliminates the requirement of nodemon as it features a built-in watch mode. It is an ideal replacement for Node.js. Bun is capable of reading .env files. It means you don’t need any 3rd party configuration. You get support for various file formats such as .js, .ts, .cjs, .mjs., tsx, etc. Bun provides you with an integrated bundling solution. It replaces web pack, parcel, rollup, rebuild, etc. Bun 1.0 also features testing libraries that remove the requirement for jest and similar tools. Bun is an npm-compatible package manager. Therefore, it naturally reduces the need for yarn and npm. High Speed and Performance Speed and performance are other aspects of Bun impressing JavaScript developers. It lets you run your code at an excellent speed. Bun 1.0 is several times faster. You won’t need to use tools like yarn, npm, and pnpm. Bun takes about 0.36 seconds to compile a code. In the case of pnpm, compilation may take up to 6.44 seconds. With npm, code compilation takes 10.58 seconds, while Yarn takes 12.08 seconds for the same task. Compared to Node.js, Bun is about four times faster. Bun 1.0 provides top-notch performance, thanks to its advanced optimization technology and efficient code bundling. In addition, it minimizes the load times for web applications. As a result, it provides a better user experience. Built-in Support for JavaScript and TypeScript Bun 1.0 provides complete support for JavaScript and TypeScript. Developers can work with both languages without using any third-party transpilers. Bun makes it easy to set up your development process. You do not need to struggle with various tools. Bun handles everything so that you can focus on coding entirely. Hot Reloading Bun 1.0 allows you to see instant updates in applications as you make changes. All credit goes to hot reloading. Bun features built-in hot reloading that enhances the development process by providing real-time updates to code and configurations. As a result, you can quickly spot all issues and fix them. With Bun, you do not need Nodemon. It automatically refreshes the server when developers run TypeScript or JavaScript code. If you have been using npm rum, you can replace it with bun run. It will reduce command execution time by at least 150 milliseconds on every run. Installation Speed It can be frustrating and time-consuming to install development tools. Fortunately, Bun 1.0 supports lightning-fast installation that reduces the setup hassle. Bun uses a global module cache system to avoid redundant downloads from the npm registry. Consequently, it uses quick system calls, available in different operating systems. Compatibility Adaptability is one of the primary Bun 1.0 features that users appreciate. This open-source bundler can effortlessly integrate with well-known server frameworks such as Hono, Koa, and Express. Web developers also get support for applications built using full-stack frameworks, including Next.js, Nuxt, Astro, Vite, Remix, etc. In addition to this, Bun 1.0 is also compatible with ESM and CommonJS. It means you can use both of them together in the same file. This feature was missing in Node.js. Conclusion Bun 1.0 is an ideal choice for developers working on JavaScript and TypeScript. It has numerous built-in features, making it a game-changer in the ever-evolving web development era. The bundle ends your dependency on complex and slow fragmented tool chains. It won’t be wrong to mention that Bun has brought revolutionary changes in the development of JavaScript projects. So these are a few worth mentioning Bun 1.0 features.
What’s New in Vue 3.3? Explore the Differences

Vue.js is a renowned JavaScript framework that helps web developers build UIs (User interfaces) and SPAs (Single-page applications). This open-source JavaScript library undergoes updates from time to time. It has released various versions so far. Lately, on May 11, 2023, Vue announced its new version, i.e., Vue 3.3. Numerous developers are keen to learn what’s new in Vue 3.3. If you’re one of them, here is the comprehensive guide. Vue 3.3 Updates Vue is evolving fast, and with each new version, it brings a lot of improvements. In version Vue 3.3, you will notice the following features and enhancements. 1. Improvements in TypeScript TypeSupport Improvement in TypeScript is one of the significant improvements in Vue.js 3.3. It helps users write type-safe in Vue applications. Earlier, they could use only local types like type literals and interfaces in the type parameter position of the defineProps and defineEmits compiler macros. With Vue 3.3 updates, this issue has been resolved. The Vue compiler is now capable of handling both imported types and a limited set of complex types. The type interface for reactive properties is more accurate in this new version of Vue. It naturally minimizes the possibility of type-related errors. <script setup lang="ts"> import type { Props } from './foo' // imported + intersection type defineProps<Props & { extraProp?: string }>() </script> 2. Support for Different Data Types Vue 3.3 features a plethora of improvements. One significant among them is support for different data types. It gives you support for generic components. Now users can easily make reusable components that work with various data types smoothly. This feature is highly beneficial for those developing components that deal with varying data types. What makes it better is users can do this without compromising on safety. 3. Suspense Vue 3.3 has introduced the Suspense feature, allowing the users to handle asynchronous operation seamlessly in the components. The user can define fallback content to display while waiting for data to load. The suspense feature of Vue 3.3 can significantly improve your user experience, especially when your component needs to fetch data from an API. <template> <Suspense> <template #default> <AsyncComponent /> </template> <template #fallback> <LoadingSpinner /> </template> </Suspense> </template> 4. Improved Syntax for defineEmits Another notable improvement you can see in this latest version of Vue.js is enhanced syntax for the defineEmits function. It enables you to declare the events that a component releases. The function improves the readability of code and lets you define Emits with an object notation. It helps users to make a better representation of the emitted events inside the component. <script> import { defineEmits } from 'vue'; export default { emits: defineEmits(['click', 'input']), }; </script> In the above code snippet, the ‘emits’ property utilizes the ‘defineEmits’ function in conjunction with an array having event names. This approach guarantees a concise declaration of the component’s emitted events. Therefore, it enhances the readability of the code. 5. defineModel: Streamlining Two-way Binding Components The innovative defineModel function introduced in Vue 3.3 makes it easy to create two-way binding components. It provides a user-friendly method for defining the modelValue prop and update:modelValue event. Generally, it is used in v-model bindings. 6. Easy Access to Reactive Props Vue 3.3 has simplified the access to reactive props inside a component’s setup function. This improvement streamlines the process of managing props, supporting easy writing and reading of code and conciseness. <script> import { reactive } from 'vue'; export default { props: { user: Object, }, setup(props) { const { user } = props; // Destructuring reactive props // Utilizing the destructured user object console.log(user.name); // … }, }; </script> The provided code snippet destructures the user prop within the setup function. It allows direct access to its properties. It helps in simplifying the code readability. 7. Improvements in Devtools Devtools in Vue 3.3 have undergone various improvements. Some of the major updates are as per below. Event Inspector The Event Inspector in Vue 3.3 gives better insights into the event system of applications. It lets you inspect event listeners and find out which components are listening to particular events. Pinning Components You can now “pin” components in Vue. As a result, it is easier to keep track of a particular component while steering through an application’s component tree. 8. Type Slots with defineSlots Vue 3.3 features an innovative function named defineSlots. As the name indicates, it encourages precise specification of slot types within a component. This feature boosts type safety in components. Furthermore, it improves IDE support for slot content. <template> <div> <slot name="header" :data="headerData" /> <slot :data="defaultData" /> </div> </template> <script> import { defineSlots } from 'vue'; export default { slots: defineSlots({ header: { data: { type: Object, required: true, }, }, default: { data: { type: String, required: false, default: 'Default Slot Content', }, }, }), }; </script> In the above code snippet, the slots use the defineSlots function to define the type of slots used in the component. It helps developers to do type-checking and relish autocompletion during leveraging slots. Conclusion In the ever-involving world of web development, it is necessary to keep pace with cutting-edge innovations. What’s new in Vue 3.3 is worth exploring for web developers. Vue.js has been constantly improving to empower users and provide them with a better experience. The Vue 3.3 updates have brought substantial improvement in TypeScript support and APIs. You can definitely consider using Vue 3.3 for your next project. Unlock the boundless opportunities with Vue 3.3. These are a few major updates in Vue 3.3. For complete details, you can refer to Vue 3.3 release notes.
Keras Core 3.0 — Pioneering the Next Frontier in Deep Learning APIs

In the dynamic landscape of artificial intelligence, where breakthroughs occur in rapid succession and the boundaries of what’s possible are constantly pushed, the Keras framework has emerged as a steadfast companion for machine learning practitioners and researchers. With the advent of Keras Core 3.0, the framework embarks on a transformative journey, poised to redefine the very essence of capabilities, performance, and adaptability, and solidify its position as a trailblazer in the realm of deep learning. This article delves into the evolution of Keras, highlights the remarkable features of version 3.0, and explores its compatibility with various backends. Understanding Keras — A Journey from Inception to Innovation Keras, born from the visionary mind of François Chollet in 2015, swiftly rose to prominence as a high-level neural networks API known for its intuitive design and unparalleled experimentation agility. Its initial incarnation and subsequent integration with TensorFlow marked a pivotal moment, propelling Keras into the limelight of machine learning tools. As the AI landscape evolved, Keras adapted in tandem, shaping itself to meet the diverse demands of an ever-expanding user community. Now, with the unveiling of Keras Core 3.0, this evolutionary saga culminates in a symphony of enhancements that not only elevate the framework’s capabilities but also redefine its role as an indispensable asset in the arsenal of AI practitioners. Redefining Possibilities — Unveiling Keras 3.0’s Game-Changing Features Embracing the Multi-Backend Landscape Keras 3.0 emerges as a trailblazer with its unprecedented support for multiple backends. While its roots are anchored in TensorFlow, this version casts a wider net, inviting frameworks like jAX and PyTorch into its fold. The result? A harmonious coexistence that empowers researchers and practitioners to wield their preferred framework without renouncing the prowess of Keras. Precision Perfected — Advanced Performance Optimization Keras Core 3.0 doubles down on performance optimization, seamlessly weaving techniques like mixed-precision training and distributed training into its fabric. The result is a turbocharged training process and maximized hardware resource utilization. These optimization strategies work behind the scenes, enabling users to focus on the art of model development and experimentation, confident that the framework is orchestrating the complex ballet beneath. Expanding the Horizons — A Flourishing Ecosystem The Keras ecosystem flourishes with renewed vigour in Keras 3.0. The framework’s enhanced support for KerasCV and KerasNLP, specialized libraries tailored for computer vision and natural language processing, empowers it to excel in these domains. This synergy doesn’t just streamline the development process; it equips users with an extensive toolkit to conquer the intricate challenges inherent in these fields. Uniting the Diverse — Cross-Framework Compatibility Keras Core 3.0 ushers in an era of harmony across deep learning frameworks. Models crafted in Keras effortlessly traverse the boundaries between TensorFlow, jAX, and PyTorch backends, reflecting a unification in an ecosystem historically divided. This seamless compatibility erases barriers, fostering an environment of collaboration and experimentation, where diverse tools coalesce to drive innovation. Evolution by Design — The Philosophy of Progressive Disclosure Keras 3.0 embodies the ethos of progressive disclosure, catering to both novices and seasoned practitioners. The API unfolds in a manner that facilitates the gentle onboarding of newcomers while gradually unveiling the advanced features craved by experts. This balanced approach ensures Keras remains accessible and indispensable, irrespective of users’ proficiency levels. A Stateless Symphony of Design — The Stateless API Paradigm The introduction of the stateless API marks a paradigm shift in Keras 3.0. Aligned with the trend of integrating functional programming concepts in deep learning, this design choice fosters modular architecture, encourages code reusability, and champions clean code organization. This leap not only elevates the development experience but also fortifies code maintenance and collaborative prowess. Navigating the Possibilities — Keras for TensorFlow, jAX, and PyTorch Embarking on the Voyage: Installation Embarking on the journey with Keras Core 3.0 is an effortless endeavour. Installation guides for each supported backend are readily available in the official documentation, providing users the freedom to opt for the backend that resonates with their ethos and project requisites. This adaptability cements Keras as an indispensable entity amid the ever-shifting currents of AI technology. For installation, $ pip install keras-core import keras_core as keras Aligning with the Core: Backend Configuration Configuring the backend is a seamless ritual, often requiring a mere few lines of code. This configuration determines the engine propelling Keras—be it TensorFlow, jAX, or PyTorch. This flexibility empowers users to fluidly transition between backends, paving the way for efficient exploration and experimentation. Run the following command for backend configuration: $ export KERAS_BACKEND="jax" $ python train.py Or $ KERAS_BACKEND=jax python train.py Mastery in Action: Integrating KerasCV and KerasNLP The integration of KerasCV and KerasNLP into Keras Core 3.0 paints a transformative landscape. KerasCV brings forth a symphony for computer vision tasks, providing dedicated APIs and pre-fabricated models for image classification, object detection, and segmentation. Meanwhile, KerasNLP empowers users to navigate the challenges of natural language processing with access to cutting-edge language models, tokenization tools, and sequence manipulation layers. And here is some KerasCV usage example: import keras_cv import keras_core as keras filepath = keras.utils.get_file(origin="https://i.imgur.com/gCNcJJI.jpg") image = np.array(keras.utils.load_img(filepath)) image_resized = ops.image.resize(image, (640, 640))[None, …] model = keras_cv.models.YOLOV8Detector.from_preset( "yolo_v8_m_pascalvoc", bounding_box_format="xywh", ) predictions = model.predict(image_resized) A Confluence of Innovation: In the ever-accelerating tapestry of deep learning, Keras Core 3.0 emerges as a beacon of innovation and adaptability. With its embrace of multiple backends, advanced performance optimization, amplified ecosystem, cross-framework harmony, philosophy of progressive disclosure, and the advent of the stateless API, Keras 3.0 redefines itself as the quintessential deep learning API. It resonates across the spectrum of users—novices venturing forth and experts charting the boundaries of possibility. As the grand symphony of deep learning unfolds, Keras Core 3.0 remains a steadfast companion, empowering developers to manifest their visions with unmatched finesse and precision.
GitOps Explained — Principles, Deployment, and Best Practices

In the ever-evolving landscape of software development, efficient deployment practices have become crucial to stay ahead of the competition and deliver high-quality products. GitOps has emerged as a cutting-edge methodology, fostering collaboration, scalability, and reliability. As it leverages version control systems like Git, GitOps enables teams to maintain a declarative representation of the desired system state, streamlining the deployment process and ensuring consistency across different environments. From understanding the core components of GitOps to implementing the most effective deployment strategies, this article aims to equip readers with the knowledge and tools to excel in the dynamic world of modern software deployment. So, let’s get started! What is GitOps? — Core Components to Excel GitOps is an advanced software deployment paradigm that revolves around the principle of “desired state” and Git version control system. The core concept involves describing the desired configuration and state of a system declaratively and storing it in a Git repository. All changes to the system, whether they pertain to application code or infrastructure settings, are represented as Git commits in the repository. The Git repository serves as the single source of truth, reflecting the actual state of the system. CI/CD pipelines, tightly integrated with the Git repository, automatically detect changes and reconcile the system state with the desired state defined in Git. The entire deployment process is thus version-controlled and auditable. CI/CD (Continuous Integration and Continuous Deployment) Continuous Integration and Continuous Deployment (CI/CD) is a fundamental aspect of GitOps. CI/CD pipelines automate the process of building, testing, and deploying code changes to production or staging environments. By integrating version control systems with CI/CD pipelines, GitOps ensures that every change made to the codebase goes through automated testing and verification before being deployed, enhancing the overall quality and reliability of the software. IaC (Infrastructure as Code) Infrastructure as Code (IaC) is a key principle in GitOps. It involves managing infrastructure configurations in a version-controlled manner, just like application code. As it describes the desired infrastructure state in code, GitOps allows teams to automate the provisioning of infrastructure resources. This approach eliminates manual setup and reduces the risk of configuration drift, leading to more predictable and reproducible deployments. MRs and PRs (Merge Requests and Pull Requests) Merge Requests (MRs) in GitLab or Pull Requests (PRs) in GitHub play a crucial role in the GitOps workflow. They serve as collaboration platforms for code reviews and discussions among team members. Before changes are applied, they undergo thorough review, testing, and validation through MRs or PRs, ensuring that only well-tested and approved changes are merged into the main codebase. Principles of GitOps Declarative System The declarative system is a fundamental concept in GitOps. Instead of defining the sequence of actions to achieve a particular state, GitOps focuses on describing the desired end state of the system. The Git repository serves as the single source of truth, containing all the necessary configurations to achieve that state. As a result, GitOps ensures that the system converges to the desired state automatically, making it easier to manage and audit changes. System State Captured in a Git Repository GitOps relies on maintaining a Git repository as the central repository for the desired system state. All changes, whether related to infrastructure or application code, are committed and version-controlled in the repository. This approach provides a historical record of changes, enabling teams to track the evolution of the system and easily roll back to a previous known state if needed. Automatic Deployment With GitOps, deployments are automated based on changes to the Git repository. Whenever a new commit is pushed to the repository, the system automatically applies the changes to the target environment. This automation reduces manual intervention, minimizes the risk of human errors during deployments, and ensures a consistent and reliable deployment process. GitOps Deployment Strategies Rolling Strategy The Rolling Strategy is a deployment approach where new changes are incrementally rolled out to the target environment while the existing version remains operational. This gradual deployment minimizes downtime and allows for easy rollbacks if issues arise during the deployment process. Canary Deployment Canary Deployment is a technique where a small subset of users or servers receives the new changes while the majority continues to use the existing version. This approach helps validate the changes in a real-world environment with reduced risk. If the canary group shows positive results, the changes are gradually rolled out to the entire system, ensuring a smooth transition. Blue-Green Deployment Blue-Green Deployment involves maintaining two identical environments—blue and green. The current version of the application runs in one environment (e.g., blue), while the new version is deployed to the other (e.g., green). Once the green environment is thoroughly tested and verified, traffic is switched from the blue to the green environment, making it the new production version. This approach enables seamless rollbacks if issues are discovered during the deployment. A/B Deployment A/B Deployment, also known as Feature Toggling, allows for deploying multiple versions of a feature simultaneously. This approach enables teams to test different implementations or user experiences and analyze their performance and impact on users. By gradually exposing different features to different user groups, A/B Deployment allows for data-driven decision-making and fine-tuning of features before full rollout. GitOps Best Practices Avoid Mixed Environments Maintain clear separation between development, staging, and production environments. Avoid mixing different configurations or states, as this can lead to unpredictable outcomes and make it challenging to identify the root cause of issues. Separating environments ensures that changes are tested thoroughly in isolated environments before reaching production. Leverage the Request Discussion Encourage collaboration and knowledge sharing among team members by using MRs or PRs as platforms for discussions. This ensures that all changes are thoroughly reviewed, tested, and approved by relevant stakeholders before being deployed. Discussions within MRs or PRs provide valuable feedback and foster a culture of continuous improvement. Policy as Code Implementing policies as code helps ensure compliance with organizational standards and best practices. Policies defined in code are version-controlled and can be automatically enforced during
NetDevOps — A Comprehensive Guide with Components and Obstacles
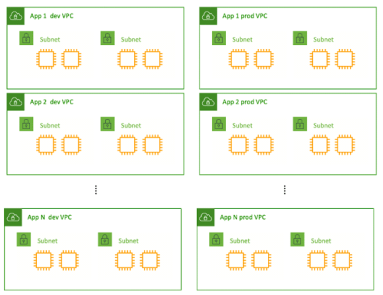
Considering the automation through Agile development processes, the software development industry has experienced a massive shift towards NetDevOps. The credit goes to its underlying network infrastructure offering network automation to fast-paced modern businesses. Since the non-DevOps approach hovers around tools, developers may experience a lack of traceability, testing, and collaboration. Here NetDevOps can help you cop with these limitations and eliminate security vulnerabilities while ensuring expected performance. Similarly, there’s a glut of things you need to know about NetDevOps if you’re looking to incorporate it into your development process. This guide will lead you to the various NetDevOps components and obstacles for a better understanding. What is NetDevOps and Why is it Worth Using? As the term describes itself, NetDevOps is a technical blend of Networking and DevOps. It streamlines the DevOps principles for the deployment and management of network services. If we dig deeper, NetDevOps apply CI/CD DevOps concepts to networking activities for faster delivery. In addition to this, its automated workflows bolster the abstraction, codification, and Infrastructure as Code (IaC) implementation. NetDevOps also eliminate the configuration drift to embed quality and resiliency within the network. In a nutshell, it improves agility by driving clear workflows aiding auditing, governance, and troubleshooting. Challenges You May Face During NetDevOps Development Risk Aversion One of the challenges that organizations may face during NetDevOps development is risk aversion. Many companies are hesitant to adopt new technologies and practices due to the fear of potential failures or disruptions to their existing network infrastructure. This risk aversion can hinder the adoption of NetDevOps methodologies, which emphasize automation, continuous integration, and continuous delivery. To address this challenge, organizations need to focus on building trust by demonstrating the benefits and success stories of NetDevOps implementation. Technical Debt Technical debt refers to the accumulated shortcuts, workarounds, and suboptimal code or configurations that result from rushed or incomplete implementation of network automation processes. This can lead to various issues, including increased complexity, reduced maintainability, and decreased scalability. To mitigate technical debt, organizations should prioritize code quality, conduct regular code reviews, and follow established best practices and coding standards. Implementing automated testing frameworks and leveraging continuous integration and delivery pipelines can help identify and address technical debt early in the development process. Skills Shortage NetDevOps development requires a unique set of skills that combine network engineering, software development, and automation expertise. However, finding individuals with a strong skill set in these areas can be challenging due to the shortage of qualified professionals. To address this issue, organizations can invest in training and upskilling their existing network and IT teams. This can include providing access to relevant courses, certifications, and hands-on training programs. Collaboration with external training providers or universities can also help bridge the skills gap. Documentation Effective documentation plays a crucial role in NetDevOps development, as it ensures that network configurations, automation workflows, and troubleshooting processes are well-documented and accessible to the team. However, maintaining up-to-date and comprehensive documentation can be challenging, especially when changes occur rapidly in dynamic network environments. Organizations can address this challenge by adopting documentation frameworks and tools that facilitate automated documentation generation. Version control systems, wiki platforms, and collaborative document editing tools can also help streamline the documentation process. Unstandardized Data NetDevOps development relies on gathering and analyzing network data to drive automation and decision-making processes. However, network data can be highly diverse and unstandardized, making it challenging to extract meaningful insights and build reliable automation workflows. Organizations should invest in data normalization and standardization techniques to ensure consistency and compatibility across different data sources. This can include using standardized data models, implementing data transformation pipelines, and leveraging data analytics tools for data cleansing and preprocessing. Tool Limitations NetDevOps development often requires the use of various tools and technologies, including network configuration management systems, automation frameworks, and orchestration platforms. However, tool limitations can arise, such as a lack of integration capabilities, limited scalability, or inadequate support for specific network devices or protocols. To overcome these challenges, organizations should thoroughly evaluate and choose tools that align with their specific requirements and network environment. They should also consider open-source solutions that offer flexibility and community support. Top NetDevOps Components Modularity Modularity is a key component of NetDevOps, enabling the creation of flexible and scalable network architectures. By breaking down network systems into modular components, organizations can easily adapt and scale their networks as per evolving requirements. Modularity facilitates the deployment of microservices, allowing for the independent development and deployment of specific network functionalities. This approach not only enhances agility but also simplifies troubleshooting and maintenance, as issues can be isolated to specific modules. For instance, using containerization technologies like Docker, network functions can be encapsulated within lightweight, portable containers, ensuring consistent behavior across different environments. Example 1 – Multiple applications in a single VPC network architecture Example 2 – Single application per VPC network architecture Cultural Changes Cultural changes play a crucial role in successfully implementing NetDevOps. Traditionally, network and operations teams operated in silos, with limited collaboration between them. However, NetDevOps encourages a cultural shift towards increased collaboration, communication, and shared responsibility. By fostering a DevOps culture, organizations can break down barriers between different teams, promoting a collaborative approach to network management. This cultural shift involves embracing shared goals, establishing cross-functional teams, and encouraging continuous learning and skill development. Automation and Infrastructure as Code Automation and Infrastructure as Code (IaC) are pivotal components of NetDevOps, enabling organizations to achieve faster and more efficient network deployments. Automation eliminates manual, error-prone tasks and accelerates the provisioning and configuration of network devices. Tools like Ansible, Puppet, or Chef enable the automation of network device configurations, ensuring consistency and reducing human errors. Infrastructure as Code allows network infrastructure to be defined and managed through machine-readable configuration files, promoting version control and reproducibility. Continuous Integration/Continuous Deployment Continuous Integration/Continuous Deployment (CI/CD) practices are integral to NetDevOps, enabling organizations to rapidly and reliably deploy network changes. CI/CD pipelines automate the process of integrating code changes, testing them, and deploying them to